Es kommt oft vor, dass es notwendig ist, ein bestimmtes soziales Phänomen zu analysieren und Informationen über ihn zu erhalten. Solche Aufgaben treten häufig in der Statistik auf und statistische Studien. Überprüfen Sie das völlig bestimmte soziales Phänomen am häufigsten unmöglich. Wie erfahren Sie zum Beispiel die Meinung der Bevölkerung oder all den Einwohnern einer bestimmten Stadt auf irgendeine Frage? Bitten Sie absolut alles - der Fall ist fast unmöglich und sehr mühsam. In solchen Fällen brauchen wir eine Probe. Dies ist genau das Konzept, an dem fast alle Forschung und Tests basieren.
Was ist eine Probe?
Bei der Analyse eines bestimmten sozialen Phänomens ist es notwendig, Informationen darüber zu erhalten. Wenn Sie eine Forschung annehmen, kann darauf hingewiesen werden, dass die Studie und Analyse nicht jeder Einheit eines Satzes eines Forschungsobjekts unterliegen. Es wird nur ein bestimmter Teil der gesamten Gesamtheit berücksichtigt. Dieser Prozess ist das Beispiel: Wenn nur bestimmte Einheiten des Sets untersucht werden.
Natürlich hängt viel von der Art der Probenahme ab. Es gibt jedoch grundlegende Regeln. Die Hauptsache ist, dass die Auswahl des Aggregats absolut zufällig sein muss. Aggregateinheiten, die verwendet werden, sollten aufgrund eines Kriteriums nicht ausgewählt werden. In grobem Sprechen, wenn Sie eine Gesamtheit der Bevölkerung einer bestimmten Stadt sammeln müssen und nur Männer nehmen müssen, ist das Studium ein Fehler, da die Auswahl nicht versehentlich ausgegeben wurde, sondern vom Geschlecht ausgewählt wurde. Fast alle Probenmethoden basieren auf dieser Regel.
Auswahlregeln
Damit das ausgewählte Aggregat die Hauptqualitäten des gesamten Phänomens widerspiegelt, sollte sie nach bestimmten Gesetzen gebaut werden, wo sich die folgenden Kategorien konzentriert:
- probe (selektives Aggregat);
- durchschnittsbevölkerung;
- repräsentativität;
- repräsentativer Fehler;
- eine Einheit von Aggregat;
- methoden zum Erstellen einer Probe.
Merkmale der selektiven Beobachtung und der Probenahme sind wie folgt:
- Alle erhaltenen Ergebnisse basieren auf mathematischen Gesetzen und Regeln, dh mit ordnungsgemäßen Forschungen und unter den richtigen Berechnungen werden die Ergebnisse nicht subjektiv verzerrt.
- Es gibt die Gelegenheit viel schneller und mit weniger Zeit und Ressourcen, um das Ergebnis zu erzielen, das Studium nicht das gesamte Array von Ereignissen, sondern nur von ihrem Teil.
- Es kann angewendet werden, um verschiedene Objekte zu studieren: von bestimmten Fragen, zum Beispiel Alter, dem Boden der Gruppe, an der Sie interessiert sind, an der Studie Öffentliche Meinung oder das Niveau der materiellen Unterstützung der Bevölkerung.
Selektive Beobachtung.
Probe - es ist statistische Beobachtung.In dem die Studie nicht der gesamten Gesamtheit des Studiums unterliegt, aber nur einige, die auf bestimmte Weise ausgewählt werden, und die Ergebnisse der Studie dieses Teils sind auf den gesamten Satz verteilt. Dieser Teil wird als selektiver Set bezeichnet. Dies ist der einzige Weg, um ein großes Array des Objekts der Studie zu studieren.
Die selektive Beobachtung kann jedoch nur in Fällen verwendet werden, in denen nur eine kleine Gruppe von Einheiten untersucht werden muss. Beim Studieren des Verhältnisses von Männern an Frauen in der Welt wird beispielsweise die selektive Beobachtung verwendet. Aus offensichtlichen Gründen ist es unmöglich, jeden Bewohner unseres Planeten berücksichtigen zu können.
Aber mit derselben Studie, aber nicht alle Bewohner der Erde, sondern eine bestimmte 2-Zoll-Klasse an einer bestimmten Schule, eine bestimmte Stadt, ein bestimmtes Land, kann ohne selektive Beobachtung verzichten. Um das gesamte Array des Objekts der Studie zu analysieren, ist es durchaus möglich. Es ist notwendig, Jungen und Mädchen dieser Klasse zu berechnen - das ist das Verhältnis.

Selektives und allgemeines Aggregat
In der Tat ist alles nicht so schwierig, wie es sich anhört. In jedem Untersuchungsgegenstand gibt es zwei Systeme: Allgemeines und selektives Aggregat. Was ist es? Alle Einheiten beziehen sich auf General. Und zu selektiv - diese Einheiten des gesamten Gesamtaggregats, das für die Probe entnommen wurde. Wenn alles richtig gemacht wird, ist der ausgewählte Teil ein reduziertes Layout des gesamten (allgemeinen) Sets.
Wenn wir über das allgemeine Aggregat sprechen, können nur zwei Arten davon unterschieden werden: ein bestimmtes und unbestimmter allgemeiner Aggregat. Es hängt davon ab, ob die Gesamtzahl der Einheiten dieses Systems bekannt ist oder nicht. Wenn dies ein bestimmtes allgemeines Set ist, lässt sich die Probe aufgrund dessen, was bekannt ist, welchen Prozentsatz der Gesamtzahl der Einheiten bekannt ist.
Dieser Moment ist in der Forschung sehr notwendig. Wenn Sie beispielsweise den Prozentsatz von Süßwarenprodukten von schlechter Qualität in einer bestimmten Fabrik untersuchen müssen. Angenommen, das allgemeine Aggregat ist bereits definiert. Es ist nur bekannt, dass dieses Unternehmen pro Jahr 1000 Süßwaren produziert. Wenn Sie eine Probe von 100 zufälligen Süßwarenzeugnissen von diesen Tausend erstellen und sie an die Untersuchung senden, ist der Fehler minimal. In grobem Gespräch wurde eine Studie auf 10% aller Produkte verwiesen, und auf den Ergebnissen können wir unter Berücksichtigung des Fehlers der Repräsentativität über die schlechte Qualität aller Produkte sprechen.
Und wenn Sie eine Probe von 100 Süßwarenprodukten aus einem unbestimmten allgemeinen Aggregat haben, wo sie tatsächlich zugelassen wurden, sind 1 Million Einheiten, das Ergebnis der Probe und der Forschung selbst, kritisch und ungenau. Fühlst du den Unterschied? Daher ist die Gewissheit der Allgemeinbevölkerung in den meisten Fällen äußerst wichtig und beeinträchtigt das Ergebnis der Studie stark.

Repräsentativität von Aggregat
Nun eines der wichtigsten Probleme - was sollte das Beispiel sein? Dies ist der Hauptmoment der Studie. Zu diesem Zeitpunkt ist es notwendig, die Probe zu berechnen und Einheiten auszuwählen gesamt drin. Das Set wurde ordnungsgemäß ausgewählt, wenn bestimmte Merkmale und Merkmale der allgemeinen Bevölkerung in selektiv bleiben. Das heißt repräsentativ.
Mit anderen Worten, wenn nach der Auswahl Teile dieselben Trends und Merkmale behält, dass der gesamte Betrag der untersuchten, dann als repräsentativ bezeichnet wird. Aber nicht jedes spezifische Beispiel kann aus einer repräsentativen Gesamtheit ausgewählt werden. Es gibt solche Objekte der Studie, deren Probe einfach nicht repräsentativ sein kann. Von hier und dem Konzept eines Repräsentativitätsfehlers tritt auf. Aber wir werden über dieses wenig mehr reden.
So erstellen Sie ein Beispiel
Daher, dass die Repräsentativität maximal ist, weisen Sie drei grundlegende Beispielregeln zu:

Fehler (Fehler) Repräsentativität
Die Hauptmerkmale der Qualität der ausgewählten Probe ist das Konzept des "repräsentativen Fehlers". Was ist es? Dies sind bestimmte Abweichungen zwischen Indikatoren der selektiven und festen Beobachtung. In Bezug auf den Fehler ist die Repräsentativität in zuverlässiges, gewöhnliches und ungefähres unterteilt. Mit anderen Worten, zulässigen Abweichungen in Höhe von bis zu 3%, 3 bis 10% bzw. von 10 bis 20%. Obwohl es in der Statistik wünschenswert ist, dass der Fehler 5-6% nicht überschreitet. Ansonsten gibt es einen Grund, über die unzureichende Repräsentativität der Probe zu sprechen. Um die Dringlichkeit der Repräsentativität zu berechnen und wie sie die selektive oder allgemeine Bevölkerung auswirkt, werden viele Faktoren berücksichtigt:
- Die Wahrscheinlichkeit, mit der es notwendig ist, ein genaues Ergebnis zu erzielen.
- Die Anzahl der Einheiten des selektiven Aggregats. Wie bereits erwähnt, sind die weniger Einheiten ein Probe, desto größer wird ein Repräsentativitätsfehler und umgekehrt.
- Die Einheitlichkeit der Gesamtheit unter der Studie. Je heterogener ist eine Gesamtheit, desto größer ist die Unsicherheit der Repräsentativität. Die Möglichkeit des Aggregats, repräsentativ zu sein, hängt von der Einheitlichkeit aller seiner Komponenten ab.
- Die Methode der Auswahl von Einheiten in das selektive Set.
In bestimmten Studien wird der Prozentsatz des Durchschnittsfehlers in der Regel vom Forscher selbst auf der Grundlage des Beobachtungsprogramms und gemäß den Daten der zuvor durchgeführten Studien festgelegt. In der Regel wird ein gültiger Abtastfehler innerhalb von 3-5% als zulässiger Fehler (Repräsentativität) betrachtet.

Mehr - nicht immer besser
Es lohnt sich auch, daran zu erinnert, dass die Hauptsache in der Organisation der selektiven Beobachtung, sein Volumen auf ein zulässige Minimum zu bringen ist. Es sollte nicht streben, die Grenzen des Abtastfehlers übermäßig zu verringern, da dies zu einer ungerechtfertigten Erhöhung der Größe dieser Proben führen kann, und daher auf eine Erhöhung der Ausgaben auf selektiver Beobachtung.
Gleichzeitig ist es unmöglich, die Größe der Dringlichkeit der Repräsentativität übermäßig zu erhöhen. In der Tat, in diesem Fall, obwohl es eine Abnahme der Menge an selektivem Aggregat ergibt, führt dies zu einer Verschlechterung der Genauigkeit der erzielten Ergebnisse.
Welche Fragen werden normalerweise vor dem Forscher gestellt?
Jede Studie, wenn es durchgeführt wird, dann zu einem bestimmten Zweck und um einige Ergebnisse zu erhalten. Bei der Durchführung einer Beispielstudie werden in der Regel anfängliche Fragen eingesetzt:

Methoden zur Auswahl von Forschungseinheiten in der Probe
Nicht jedes Beispiel ist dargestellt. Manchmal unterscheidet sich das gleiche Zeichen im Allgemeinen im Allgemeinen und in seinen Teilen. Um repräsentativen Anforderungen zu erreichen, ist es ratsam, verschiedene Probtechniken zu verwenden. Darüber hinaus hängt die Verwendung eines oder einer anderen Methode von bestimmten Umständen ab. Unter diesen Probenerzeugungstechniken werden unterschieden:
- zufällige Auswahl;
- mechanische Auswahl;
- typische Auswahl;
- selektion (Nest).
Zufältige Auswahl ist ein System von Maßnahmen, das auf die zufällige Auswahl von Aggregateinheiten abzielt, wenn die Wahrscheinlichkeit des Einstiegs in die Probe allen Einheiten der allgemeinen Bevölkerung entspricht. Es ist ratsam, diese Technik nur im Falle der Homogenität anzuwenden, und eine kleine Anzahl von inhärenten Anzeichen. Ansonsten reflektiert einige charakteristische Merkmale nicht in der Probe. Anzeichen einer Zufallsauswahl basieren auf allen anderen Wegen, um eine Probe zu erstellen.
Bei der mechanischen Auswahl von Einheiten wird durch ein bestimmtes Intervall ausgeführt. Wenn Sie ein Beispiel für bestimmte Verbrechen bilden müssen, können Sie je nach Gesamtzahl der Gesamtzahl und der Mustergröße von allen statistischen Bilanzierungskarten für eingetragene Verbrechen zurückziehen. Der Nachteil dieses Verfahrens besteht darin, dass vor der Auswahl erforderlich ist, um die volle Rechnungslegung von Aggregateinheiten, dann auf Rang und erst danach möglich zu sein, mit einem bestimmten Intervall zu probieren. Diese Methode dauert viel Zeit, sodass es nicht oft verwendet wird.

Typische (zöhne) Auswahl ist eine Art von Probenahme, in der die allgemeine Bevölkerung auf ein bestimmtes Zeichen in homogene Gruppen unterteilt ist. Manchmal nutzen Forscher andere Begriffe anstelle von Gruppen: "Bezirke" und "Zonen". Dann wird von jeder Gruppe in zufälliger Reihenfolge eine bestimmte Anzahl von Einheiten im Verhältnis zum spezifischen Gewicht der Gruppe im Gesamtaggregat ausgewählt. Die typische Auswahl wird oft in mehreren Bühnen durchgeführt.
Die serielle Auswahl ist ein Verfahren, in dem die Auswahl der Einheiten von Gruppen (Serie) durchgeführt wird, und alle Einheiten der ausgewählten Gruppe (Serie) unterliegen der Umfrage. Der Vorteil dieses Verfahrens besteht darin, dass manchmal einzelne Einheiten komplizierter als eine Serie ausgewählt wird, beispielsweise beim Studieren einer Person, die einen Satz serviert. Im Rahmen ausgewählter Bereichen wenden die Zonen die Untersuchung aller Einheiten ausnahmslos an, beispielsweise die Untersuchung aller Personen, die in einer bestimmten Institution einen Satz servieren.
sampling-Typen:
Tatsächlich zufällig;
Mechanisch;
Typisch;
Serie;
Kombiniert
Tatsächlich zufällige Probees ist die Auswahl von Einheiten aus dem allgemeinen Aggregat zufällig, ohne Elemente des Systems. Vor der Erzeugung der selbstzuführlichen Auswahl ist jedoch sicherzustellen, dass alle Einheiten der allgemeinen Bevölkerung absolut gleiche Chancen haben, in die Probe zu gelangen, es gibt keine Passagen, die einzelne Einheiten und dergleichen ignorieren. Es sollte auch die klaren Grenzen der allgemeinen Bevölkerung festlegen, so dass die Einbeziehung oder das Infirm der einzelnen Einheiten nicht Zweifel verursachen. Bei der Untersuchung von Studenten ist es beispielsweise notwendig, anzugeben, ob die Personen im akademischen Urlaub, Studenten von nichtstaatlichen Universitäten, Militärschulen usw. berücksichtigt werden. Bei der Untersuchung von Handelsunternehmen ist es wichtig, zu bestimmen, ob das allgemeine Aggregat Handelspavillons, kommerzielle Zelte und andere ähnliche Objekte umfasst. Eine selbstzufuelste Auswahl kann sowohl wiederholt als auch repuktiv sein. Um eine Angebotsauswahl in dem Zeichnungsvorgang durchzuführen, werden die tobenden Lots zurück in das ursprüngliche Set nicht zurückgegeben, und in Zukunft ist die Auswahl in der Zukunft nicht involviert. Bei Verwendung von Tabellen der Zufallszahlen wird die Intensivierungsrate durch den Durchgang erreicht, wenn sie in der ausgewählten Spalte oder Spalten wiederholt werden.
Mechanische Probees wird in Fällen angewendet, in denen die allgemeine Bevölkerung in irgendeiner Weise bestellt ist, d. H. Es gibt eine gewisse Reihenfolge am Standort von Einheiten (Angestellte Tabletoms, Wählerlisten, Befragungsnummern, Häuser und Wohnungen usw.).
Die allgemeine Kombination aus mechanischer Selektion kann durch die Größe des Vorzeichens oder der Korrelation mit ihr ranglinisiert werden, was die Repräsentativität der Probe erhöht. In diesem Fall ist jedoch das Risiko eines systematischen Fehlers zunehmend, der mit der Untertreibung der Werte des untersuchten Attributs verbunden ist (wenn der erste Wert aus jedem Intervall aufgezeichnet wird) oder mit seiner Überschätzung (wenn der letztere Wert aufgezeichnet wird) aus jedem Intervall). Daher ist es ratsam, von der Mitte des ersten Intervalls zu beginnen
Typische Auswahl.Diese Auswahlmethode wird in Fällen verwendet, in denen alle Einheiten der allgemeinen Bevölkerung in mehrere typische Gruppen unterteilt werden können. Während der Untersuchung der Bevölkerung können diese Gruppen beispielsweise Bereiche, soziale, alter oder bildungsgruppen, während der Umfrage der Unternehmen - ein Zweig- oder Unterbranchen, eine Form des Eigentums usw. Die typische Auswahl beinhaltet eine Probe von Einheiten aus jeder typischen Gruppe mit zufälliger oder mechanischer Weise. Da Vertreter aller Gruppen in einem oder anderen Anteil, Vertreter aller Gruppen auf die eine oder andere Weise gesucht werden, ermöglicht die Eingabe der allgemeinen Bevölkerung die Beseitigung der Wirkung der Intergroup-Dispersion auf einen durchschnittlichen Abtastfehler, der in Dieser Fall wird nur durch aufträgliche Variation bestimmt.
Die Auswahl der Einheiten an die typische Probe kann organisiert oder proportional zu dem Volumen typischer Gruppen oder proportional zur intrentueren Unterscheidung des Merkmals.
Serielle Auswahl.Diese Auswahlmethode ist bequem in Fällen, in denen die Einheiten der Gesamtheit in kleine Gruppen oder Serien kombiniert werden. Als solche Serien können Verpackungen mit einer bestimmten Anzahl von Fertigprodukten, Charge von Waren, Studentengruppen, Brigaden und anderen Vereinigungen berücksichtigt werden. Die Essenz der seriellen Probe liegt in einer zufälligen oder mechanischen Auswahl der Serie, in der eine solide Umfrage von Einheiten hergestellt wird.
Empirical gilt als eines der Hauptmittel, um soziale Beziehungen und Prozesse zu studieren. Sie bieten zuverlässige, vollständige und repräsentative Informationen.
Spezifität der Techniken.
Empirisch bietet einen Erhalt eines sachlichen Wissens. Sie tragen zur Errichtung und Verallgemeinerung der Umstände auf Kosten der vermittelten oder direkten Registrierung von Ereignissen bei, die in den in den Beziehungen gelernten Beziehungen, Objekte, Phänomenen inhärent sind. Empirische Techniken unterscheiden sich von der theoretischen Tatsache, dass das Thema der Analyse ist:
- Das Verhalten von Einzelpersonen und ihrer Gruppen.
- Menschliche Aktivität.
- Verbale Aktionen von Einzelpersonen, ihre Urteile, Ansichten, Meinungen.
Beispielstudien
Empirisches Lernen konzentriert sich immer darauf, objektive und genaue Informationen, quantitative Daten zu erhalten. In diesem Zusammenhang ist es notwendig, die Repräsentativität der Informationen sicherzustellen, wenn er erfüllt ist. Dementsprechend ist der korrekte Wert korrekt selektives Aggregat. Das Dies bedeutet, dass die Auswahl durchgeführt werden sollte, so dass die erhaltenen Daten der engen Gruppe die Trends widerspiegeln, die in der Gesamtmasse der Befragten erfolgen. Wenn zum Beispiel die Erhebung von 200-300 Personen, können die erhaltenen Daten auf alle extrapoliert werden städtische Bevölkerung. Die Indikatoren des selektiven Aggregats ermöglichen einen unterschiedlichen Ansatz für das Studium sozioökonomischer Prozesse in der Region im gesamten Land in der Region.

Terminologie
Für ein besseres Verständnis von Fragen, die sich auf selektive Forschung beziehen, ist es erforderlich, einige Definitionen zu klären. Die Beobachtungseinheit ist die direkte Informationsquelle. Sie können eine separate Person, Gruppe, Dokument, Organisation usw. sein. Das allgemeine Aggregat ist Komplex von Beobachtungseinheiten. Sie sollten alle mit dem untersuchten Problem zusammenhängen. Die direkte Analyse ist unterliegt. Die Studie erfolgt gemäß den entwickelten Methoden zum Sammeln von Informationen. Um diesen Anteil der gesamten Anordnung der Befragten zu ermitteln, verwenden Sie das Konzept des "selektiven Aggregats". Seine Eigenschaft spiegelt die Schlüsselparameter der Gesamtmasse der Personen wider, die als Repräsentativität genannt werden. In einigen Fällen gibt es keinen Zufall. Dann sprechen sie über den Fehler der Repräsentativität.
Repräsentativität bieten
Details, die mit ihm verbunden sind, werden im Rahmen der Statistiken diskutiert. Probleme zeichnen sich durch Komplexität aus, da es einerseits vorgeschlagen wird, eine quantitative Darstellung bereitzustellen, die ergibt durchschnittsbevölkerung. Das Gibt insbesondere an, dass die Gruppen von Befragten in der optimalen Anzahl dargestellt werden müssen. Die Menge sollte für die normale Darstellung ausreichend sein. Andererseits gibt es auch eine qualitative Darstellung. Es beinhaltet ein gewisses Thema, das ausgebildet ist selektives Aggregat. Das Es bedeutet, dass zum Beispiel eine Repräsentativität nicht diskutiert werden kann, wenn nur Männer interviewt sind oder nur Frauen, ältere Menschen, ältere Menschen entweder Jugendliche. Die Studie sollte in allen dargestellten Gruppen durchgeführt werden.

Charakteristische Probe
Dieser Begriff wird in zwei Aspekten berücksichtigt. Zunächst einmal ist es als Komplex von Elementen aus einem gemeinsamen Array von Menschen definiert, deren Meinung studiert wird - dies selektives Aggregat. Das Auch der Prozess der Erstellung einer bestimmten Kategorie der Befragten mit der erforderlichen Bereitstellung von Repräsentativität. In der Praxis fallen verschiedene Arten und Arten von Auswahltypen aus. Betrachte sie
Arten
Es gibt drei davon:
- Spontan selektives Aggregat. Das Eine Reihe von Befragten, die auf dem Prinzip der Freiwilligkeit ausgewählt wurden. Gleichzeitig ist die Verfügbarkeit von Einheiten aus der Gesamtmasse von Personen in eine bestimmte Studiengruppe sichergestellt. Die spontane Auswahl in der Praxis wird oft verwendet. Zum Beispiel mit Umfragen in der Presse in der E-Mail. Diese Technik hat jedoch einen erheblichen Nachteil. Es ist unmöglich, den gesamten Betrag der allgemeinen Probe qualitativ zu präsentieren. Diese Technik wird auf der Grundlage der Wirtschaft angewendet. In einigen Umfragen ist diese Option nur möglich.
- Spontan selektives Aggregat. Das Eine der wichtigsten Techniken, die in der Studie verwendet werden. Als ein Schlüsselprinzip einer solchen Auswahl ist es möglich, Möglichkeiten für jede Beobachtungseinheit sicherzustellen, von der Gesamtmasse von Individuen in eine enge Gruppe zu gelangen. Dies verwendet verschiedene Techniken. Beispielsweise kann es eine Lotterie, eine mechanische Auswahl, eine Tabelle der Zufallszahlen sein.
- Stratifizierte (Steinbruch-) Probe. Es basiert auf der Bildung eines qualitativen Modells der Gesamtmasse der Befragten. Danach wird die Auswahl der Einheiten in der selektiven Gesamtheit durchgeführt. Zum Beispiel wird es nach der Bevölkerung usw. nach Alter oder Geschlecht durchgeführt.
Ansichten
Die folgenden Proben gibt es:

zusätzlich
Proben können auch abhängig und unabhängig sein. Im ersten Fall hat das experimentelle Verfahren und die Ergebnisse, die für eine Gruppe von Befragten während ihres Ertrags erhalten werden, einen gewissen Einfluss auf den anderen. Dementsprechend beabsichtigen unabhängige Proben nicht, einen solchen Aufprall zu haben. Hier sollten Sie jedoch auf einen wichtigen Punkt achten. Eine Gruppe von Subjekten, in deren Hilfe die psychologische Untersuchung zweimal durchgeführt wurde (auch wenn es darauf abzielt, verschiedene Qualitäten, Funktionen, Funktionen) zu studieren, wird der Standard als abhängig angesehen.
Probabilistische Auswahl
Betrachten Sie einige Arten von Proben:
- Zufällig. Es beinhaltet die Homogenität des Gesamtaggregats, eine Wahrscheinlichkeit der Verfügbarkeit aller Komponenten sowie das Vorhandensein einer vollständigen Liste von Elementen. In der Regel wird während der Auswahl eine Tabelle mit Zufallszahlen verwendet.
- Mechanisch. Diese Art der zufälligen Abtastung impliziert eine Bestellung auf eine bestimmte Funktion. Zum Beispiel per Telefonnummer, in alphabetischer Reihenfolge, nach Geburtsdatum und so weiter. Die erste Komponente wird in zufälliger Reihenfolge ausgewählt. Als nächstes ist die Auswahl jedes K-Elements mit einem Schritt n. Die Größe des Gesamtaggregats wird n \u003d k * n sein.
- Stratisch. Diese Probe wird in der Inhomogenität des Gesamtaggregats verwendet. Letzteres ist in Strata (Gruppen) unterteilt. In jedem von ihnen wird die Auswahl durch mechanische oder zufällige Weise durchgeführt.
- Seriell. Die Gruppenauswahl ist versehentlich. In ihnen werden Objekte von einem Feststoff untersucht.
Unglaubliche Auswahl
Sie schlagen eine Probe vor, nicht auf dem Grundsatz der Zufall, sondern je nach subjektiven Zeichen: typisch, Zugänglichkeit, gleiche Darstellung und so weiter. Diese Kategorie enthält Auswahlmöglichkeiten:

Nuance
Um die Repräsentativität bereitzustellen, ist eine genaue und vollständige Liste von Aggregateinheiten erforderlich. Objekte der Beobachtung, in der Regel, ist eine Person. Die Auswahl aus der Liste ist besser, um Einheiten auszuführen, Nummerneinheiten und Anwenden einer Tabelle mit Zufallszahlen. Die Quasfonound-Methode wird jedoch oft oft verwendet. Es impliziert die Auswahl aus der Liste jedes N-Elements.
Beeinflussende Faktoren
Das Volumen des Aggregats wird als Anzahl seiner Einheiten bezeichnet. Laut Experten muss es nicht groß sein. Zweifellos, mehr nummer Befragte, desto genauer das Ergebnis. Zusammen mit diesem garantiert jedoch ein großer Betrag nicht immer den Erfolg. Dies geschieht beispielsweise, wenn das Gesamtanschluss der Befragten nicht einheitlich ist. Ein homogener wird als eine solche Kombination betrachtet, in der der kontrollierte Parameter beispielsweise die Alphabetisierungsrate gleichmäßig verteilt ist, dh es ist keine Leere oder Verdickung. In diesem Fall reicht es aus, mehrere Personen zu interviewen. Nach den Ergebnissen der Umfrage ist es möglich, zu dem Schluss möglich, dass die meisten Menschen eine normale Alphabetisierungsrate haben. Daraus folgt damit, dass die Auswirkungen von Informationen nicht quantitativer Zeichen sind, aber die qualitativen Merkmale des Aggregats sind insbesondere das Niveau seiner Homogenität.

Irrtümer
Sie repräsentieren die Abweichung der durchschnittlichen Parameter der Muster, die auf den Werten der Gesamtmasse der Befragten eingestellt sind. In der Praxis werden Fehler im Vergleich festgelegt. Während der Untersuchung von Erwachsenen gelten die Korrespondenz, statistische Rechnungslegung sowie die Ergebnisse der vergangenen Umfragen in der Regel. Die Steuerparameter führen in der Regel einen Vergleich der durchschnittlichen Sätze von Aggregaten (allgemein und selektiv) durch, wobei die Definition gemäß diesem Fehler und die Abnahme dieser Ablenkung als Repräsentativität bezeichnet wird.
Schlussfolgerungen
Eine selektive Studie ist eine Methode zum Sammeln von Daten zu den Installationen und dem Verhalten von Personen durch eine Umfrage mit speziell ausgewählten Befragungsgruppen. Diese Rezeption gilt als zuverlässig und wirtschaftlich, obwohl es einige Techniken erfordert. Die Basis ist ein selektiver Set. Es fungiert als ein gewisser Anteil der Gesamtmasse der Menschen. Die Auswahl erfolgt mit speziellen Techniken und zielt darauf ab, Informationen über die gesamte Gesamtheit zu erhalten. Letzteres ist wiederum durch alle möglichen öffentlichen Objekte oder der Gruppe, die untersucht wird, dargestellt. Oft ist das allgemeine Aggregat so groß, dass die Umfrage jedes Vertreters recht teuer und der lästige Prozess ist. Daher wird sein reduziertes Modell verwendet. In einem selektiven Set sind alle, die Fragebögen erhalten, enthalten, die als Befragte bezeichnet werden, die tatsächlich als Untersuchungsgegenstand fungieren. Es ist einfach eingerichtet, es ist viele Leute, die abgefragt werden.

Fazit
Die Ziele der Umfrage werden durch spezifische Kategorien bestimmt, die in der allgemeinen Bevölkerung enthalten sind. Wie für einen bestimmten Anteil der Gesamtmasse der Menschen unterliegt sie den in den Gruppen enthaltenen Themen mit Hilfe mathematischer Berechnungen. Zur Auswahl von Einheiten ist eine Beschreibung des Objekts des ursprünglichen Satzes erforderlich. Nach der Ermittlung der Anzahl der Probanden wird der Empfang oder Verfahren zum Bilden von Gruppen bestimmt. Die Ergebnisse der Umfrage ermöglichen es, das studierte Zeichen in Bezug auf alle Vertreter der gesamten Masse der Menschen zu beschreiben. Als Übung werden selektive, selektive und nicht solide Studien durchgeführt.
Das Verfahren zum Erstellen eines Beispielplans umfasst Ablaufende Lösung der drei folgenden Aufgaben:
Bestimmung des Objekts der Studie;
Bestimmung der Abtaststruktur;
Bestimmung der Probenahme.
Allgemein, objekt-Marketing-Forschung. Es ist eine Kombination von Beobachtungsobjekten, die Verbraucher, Unternehmensmitarbeiter, Intermediäre usw. abgespielt werden können. Wenn diese Gesamtheit so klein ist, dass das Forschungsteam die erforderlichen Arbeit, finanzielle und temporäre Fähigkeiten hat, um Kontakt mit jedem seiner Elemente herzustellen, ist es ziemlich realistisch, ein ständiges Studium der gesamten Bevölkerung durchzuführen. In diesem Fall können Sie durch Definieren des Objekts der Studie mit dem folgenden Verfahren (die Wahl der Datenerfassungsmethode, das Forschungsinstrument und die Kommunikationsmethode mit dem Publikum) fortfahren.
In der Praxis ist es jedoch sehr oft nicht möglich oder angemessen, ein kontinuierliches Studium der gesamten Bevölkerung durchzuführen. Dazu kann es folgende Gründe geben:
Die Unfähigkeit, den Kontakt mit einigen Elementen der Gesamtheit herzustellen;
Unangemessen große Kosten für die Durchführung einer soliden Studie oder der Verfügbarkeit finanzieller Einschränkungen, die keine solide Forschung zulassen;
Vorgeschlagene Fristen für die Forschung aufgrund eines Verlusts mit der Relevanz von Informationen oder anderen Gründen zugewiesen und nicht zulassen, was die Sammlung, Systematisierung und Analyse umfangreicher Daten für die gesamte Gesamtheit nicht ermöglicht.
Daher werden große und zerstreute Aggregate häufig durch Probenahme untersucht, unter denen, wie es allgemein bekannt ist, ein Teil des Aggregats, der dazu verstanden wird, die Gesamtheit als Ganzes zu personifizieren.
Die Genauigkeit, mit der die Probe die Gesamtheit als Ganzes widerspiegelt, hängt davon ab stichprobenstrukturen und -größe.
Unterscheiden Sie zwei Ansätze zur Probenahmestruktur - probabilistisch und deterministisch.
Probabilistischer Ansatz zur Probenahmestruktur Es geht davon aus, dass jedes Element des Aggregats mit einer bestimmten (nicht Null-) Wahrscheinlichkeit ausgewählt werden kann. Existieren verschiedene Arten Proben auf der Grundlage der Wahrscheinlichkeitstheorie (typisch, Verschachtelung usw.). Das einfachste und übliche in der Praxis ist eine einfache Zufallsmuster, in der jedes Element des Aggregats eine gleiche Wahl für die Studie hat.
Eine probabilistische Probe ist genauer, ermöglicht es dem Forscher, den Zuverlässigkeit der von ihm gesammelten Daten zu schätzen, obwohl er schwieriger und teurer ist als deterministisch.
Deterministischer Ansatz zur Probenstruktur Es geht davon aus, dass die Wahl der Elemente des Sets durch Methoden erfolgt, die entweder auf Überlegungen zu Komfort oder auf der Lösung des Forschers oder auf Eventualgruppen basieren.
zur Überlegungen BequemlichkeitEs besteht darin, die Elemente des Aggregats auf der Grundlage der Einfachheit des Kontaktierens des Kontakts mit ihnen zu wählen. Die Unvollkommenheit dieses Verfahrens ist auf die geringe Repräsentativität der erhaltenen Probe zurückzuführen, da Komfortable Elemente von Aggregat für den Forscher sind möglicherweise nicht ausreichend charakteristische Vertreter des Aggregats aufgrund einer nicht zufälligen und unvernünftigen Auswahl.
Andererseits hat die Einfachheit, Effizienz und Effizienz der von dieser Methode durchzuführenden Studie jedoch in der Praxis weit verbreitet gewonnen und vor allem, wenn vorläufige Studien durchgeführt werden, um große Probleme zu klären.
Probenahmerformationsmethode basiert bei der Entscheidung des ForschersEs besteht darin, die Elemente des Aggregats zu wählen, das seiner Meinung nach seine charakteristischen Vertreter sind. Diese Methode ist perfekter als der vorherige, da es auf der Orientierung der charakteristischen Vertreter der in der Studie der Taluität beruht, obwohl er auf der Grundlage der subjektiven Darstellungen von Forschern darüber ausgewählt wurde.
Die Methode der Abtastung basierend auf eventualnormenEs besteht darin, die charakteristischen Elemente des Aggregats gemäß den Merkmalen des früher erhaltenen Aggregats zu wählen. Diese Eigenschaften können durch Durchführung von vorläufigen Studien erzielt werden, und tragen im Gegensatz zur vorherigen Methode keine subjektive Natur. Daher ist diese Methode perfekter, ermöglicht es Ihnen, selektive Sets von nicht weniger repräsentativer als probabilistische Proben mit wesentlich weniger Überwachungskosten zu erhalten.
Die Auswahl der Probenstruktur (Annäherung an seine Bildung, die Art der probabilistischen oder rollierenden Bildung der deterministischen Probe) muss der Forscher das Volumen bestimmen, d. H. Die Anzahl der Elemente des selektiven Aggregats.
Abtastvolumen. Bestimmt die Genauigkeit der Informationenerhielt aufgrund seiner Forschung sowie die für die Durchführung von Forschung erforderlichen Kosten. Die Größe der Probe hängt davon ab Aus der Ebene der Homogenität oder Sorten der untersuchten Objekte.
Je höher die Größe der Probe, desto höher ist seine Genauigkeit und mehr Kosten für seine Umfrage. Mit einem probabilistischen Ansatz zur Abtaststruktur kann sein Volumen mit bekannten statistischen Formeln bestimmt werden, basierend auf den angegebenen Anforderungen an seine Genauigkeit.
In der Praxis werden mehrere Ansätze verwendet, um die Probenahme zu definieren:
1. willkürlicher Ansatz Basierend auf der Verwendung der "Regeln des Daumens". Zum Beispiel ist es nicht notwendig, dass die Probe 5% der Gesamtheit betragen sollte, um genaue Ergebnisse zu erzielen. Dieser Ansatz ist einfach und einfach zu erfüllen, aber es ist nicht möglich, die Richtigkeit der erzielten Ergebnisse festzulegen. Mit einer ausreichend großen Gesamtheit kann es auch sehr teuer sein.
Die Größe der Probe kann auf der Grundlage einiger vorbestimmter Bedingungen festgelegt werden. Beispielsweise weiß der Kunde der Marketing-Forschung, dass die Probe beim Studium der öffentlichen Meinung in der Regel 1000-1200 Menschen ist, also empfiehlt er dem Forscher, sich an diese Figur einzuhalten. Für den Fall, dass jährliche Studien auf einem anderen Markt abgehalten werden, verwendet es in jedem Jahr die Probe desselben Volumens. Im Gegensatz zum ersten Ansatz wird hier bei der Bestimmung des Probenvolumens eine bekannte Logik verwendet, die jedoch sehr anfällig ist.
Bei der Durchführung bestimmter Studien kann beispielsweise die Genauigkeit weniger benötigt werden, als wenn die öffentliche Meinung studiert wird, und die Summe einer Gesamtheit kann ein Vielfaches weniger als beim Studium der öffentlichen Meinung sein. Daher berücksichtigt dieser Ansatz die aktuellen Umstände nicht und kann recht teuer sein.
In einigen Fällen wird, wie das Hauptargument, bei der Bestimmung des Probenvolumens, die Kosten der Umfrage verwendet. Daher sieht das Budget der Marketingforschung bestimmte Umfragen vor, die nicht überschritten werden können. Natürlich wird der Wert der erhaltenen Informationen nicht berücksichtigt. In einigen Fällen kann jedoch eine kleine Probe ziemlich genaue Ergebnisse erzielen.
Es erscheint vernünftig, die Kosten nicht absolut zu berücksichtigen, sondern in Bezug auf die Nützlichkeit der infolge der durchgeführten Umfragen, die als Ergebnis der durchgeführten Umfragen erhalten wurden. Der Kunde und der Forscher sollten verschiedene Beispielvolumennähe und Datenerfassungsmethoden, Kosten, Kosten anlegen, berücksichtigen andere Faktoren
2. Die Größe der Probe auf der Ebene des vertraulichen Intervalls eines gültigen Fehlers, Was, wie bereits erwähnt, wird durch die zweckmäßige Genauigkeit der endgültigen Verallgemeinerungen gegeben: von erhöht auf ungefähr. Es gibt jedoch den sogenannten zufälligen Fehlern, die mit der Art von statistischen Fehlern verbunden sind. Sie werden als Fehlern der Repräsentativität von probabilistischen Proben berechnet.
V.I. Paniotto zitiert die folgenden Berechnungen der repräsentativen Probe mit den Berechtigungen des 5-prozentigen Fehlers (Tabelle 4.2).
Tabelle 4.2.
Berechnete Beispieltabelle
Für eine Kombination von mehr als 100.000 Sample beträgt 400 Einheiten. Wenn ich den allgemeinen Satz von 5 Tausend und mehr beachten werde, können Sie gemäß den Berechnungen desselben Autors die Werte des tatsächlichen Fehlers der Probe angeben, abhängig von ihrem Volumen, was sehr ist Wichtig für uns, erinnern Sie sich daran, dass der Wert des gültigen Fehlers von der Zweckforschung abhängt und optional den 5-prozentigen Niveau nähern sollte.
Tabelle 4.3.
Berechneter Tisch
|
Probenahme, wenn das allgemeine Aggregat 5000 | ||||||||
|
Istfehler in diesem Probenvolumen% |
Zusammen mit zufälligen, systematischen Fehlern sind systematische Fehler möglich. Sie hängen von der Organisation einer selektiven Prüfung ab. Hierbei handelt es sich um eine Vielzahl von Probenahme, die auf einen der Pole des selektiven Parameters versetzt ist.
3. SAMPLUNG Basierend auf statistischer Analyse . Dieser Ansatz basiert auf der Bestimmung der minimalen Abtastung auf der Grundlage bestimmter Anforderungen an die Zuverlässigkeit und Zuverlässigkeit der erzielten Ergebnisse. Es wird auch in der Analyse der Ergebnisse verwendet, die für einzelne Untergruppen erhalten werden, die als Teil der Auswahl auf dem Boden, dem Alter, dem Bildungsniveau usw. ausgebildet sind usw. Anforderungen an die Zuverlässigkeit und Genauigkeit der Ergebnisse für einzelne Untergruppen diktieren bestimmte Anforderungen an die Größe der gesamten Sample als Ganzes.
Der tathoretisch am theoretisch begründete und korrekte Ansatz zur Bestimmung des Probenvolumens basiert auf der Berechnung zuverlässiger Intervalle. Das Konzept der Variation kennzeichnet die Größe falscher (ähnlicher) Antworten der Befragten auf eine bestimmte Frage. In einem strengeren Plan wird die Variation der Werte eines beliebigen Zeichens in einem Set der Unterschied in seinen Werten aus verschiedenen Einheiten dieses Satzes in demselben Zeitraum oder in derselben Zeit bezeichnet. Antworten auf Umfragefragen werden in der Regel in Form einer Verteilungskurve dargestellt (Abb. 4.1). Mit einer hohen Ähnlichkeit sprechen die Antworten über niedrige Schwankungen (enge Verteilungskurve) und mit geringen Ähnlichkeiten mit niedrigem Ähnlichkeiten - über hohe Variationen (weite Verteilungskurve).
Als Maß an Variation wird in der Regel eine durchschnittliche quadratische Abweichung ergriffen, die den durchschnittlichen Abstand von der durchschnittlichen Bewertung der Antworten jedes Befragten auf eine bestimmte Frage charakterisiert.
Kleine Variation
Hohe Variation
Feige. 4.1. Variations- und Verteilungskurven
Da alle Marketinglösungen in der Unsicherheit akzeptiert werden, ist dieser Umstand ratsam, beim Bestimmen der Größe der Probe zu berücksichtigen. Da die Definition von studierenden Werten für eine Gesamtheit in einer engen Zeit auf der Grundlage von durchgeführt wird beispielstatistikSie sollten den Bereich (Vertrauensintervall) einstellen, der voraussichtlich für eine Gesamtheit als Ganzes geschätzt wird, und der Fehler ihrer Definition.
Das Vertrauensintervall ist der Bereich, deren extremen Punkte einem bestimmten Prozentsatz bestimmter Antworten auf einige Fragen entsprechen. Das Konfidenzintervall ist eng mit einer durchschnittlichen quadratischen Abweichung des untersuchten Attributs in der allgemeinen Bevölkerung verbunden: je mehr, desto größer ist das Vertrauensintervall, um einen bestimmten Prozentsatz der Antworten aufzunehmen.
Das Konfidenzintervall, das gleich oder 95% oder 99% ist, ist ein Standard, wenn Sie die Marketingforschung durchführen. Kein Unternehmen leitet Marketingforschung durch Bilden mehrerer Proben. Die mathematische Statistik ermöglicht es, einige Informationen über die selektive Verteilung zu erhalten, die nur Daten über Variationen einer einzelnen Probe besitzen.
Der Indikator für die Bewertung der Bewertung, der True für ein insgesetzte Set, aus der Beurteilung, von der erwartet wird, dass sie eine typische Probe sein soll, ist ein mittlerer quadratischer Fehler. Darüber hinaus ist desto mehr Abtastung, desto kleiner der Fehler. Der hohe Wert der Variation bestimmt den hohen Wert des Fehlers und umgekehrt.
Wenn es nur zwei Optionen für die zugewiesene Frage gibt, die als Prozentsatz ausgedrückt werden (eine Prozentmaßnahme), wird die Probengröße durch die folgende Formel bestimmt:

wobei n die Größe der Probe ist; z ist die normalisierte Abweichung, die auf der Grundlage des gewählten Vertrauungsniveaus bestimmt ist; P - gefundene Variation für die Probenahme; G - (100-p); E - Zulässiger Fehler.
Bei der Ermittlung des Indikators der Variation für ein bestimmtes Set, zunächst ist es ratsam, eine vorläufige qualitative Analyse der untersuchten Verbrennung durchzuführen, zunächst die Ähnlichkeit der Ähnlichkeit der Aggregateinheiten in den demografischen, sozialen und anderen Beziehungen von Interesse an dem Forscher. Es ist möglich, eine Pilotstudie durchzuführen, die Verwendung der Ergebnisse solcher in der Vergangenheit durchgeführten Studien. Bei der Verwendung eines prozentualen Umfangs der Variabilität wird berücksichtigt, dass die maximale Variabilität für P \u003d 50% erreicht wird, was der schlimmste Fall ist. Darüber hinaus beeinflusst dieser Indikator radikal nicht die Größe der Probe. Die Stellungnahme der Forschung des Kunden über das Abtastvolumen wird ebenfalls berücksichtigt.
Es ist möglich, die Probengröße basierend auf der Verwendung von Durchschnittswerten und nicht an Prozentwerten zu definieren.

wobei S eine sekundäre quadratische Abweichung ist.
In der Praxis wurden, wenn die Probe neu ausgebildet ist, und ähnliche Erhebungen wurden nicht durchgeführt, dann ist S nicht bekannt. In diesem Fall ist es ratsam, den Fehler E in den Fraktionen der Standardabweichung einzustellen. Die berechnete Formel wird umgewandelt und erwirbt das folgende Formular:
 wo
wo  .
.
Oben gab es ein Gespräch über die Aggregate sehr großer Größen. In einigen Fällen ist das Aggregat jedoch nicht groß. In der Regel, wenn die Probe weniger als fünf Prozent des Aggregats beträgt, gilt das Aggregat als groß und Berechnungen werden gemäß den obigen Regeln durchgeführt. Wenn die Größe der Probe 5% des Aggregats übersteigt, wird der letztere als klein angesehen, und die obige Formel wird durch einen Korrekturkoeffizienten eingeführt.
Die Mustergröße in diesem Fall ist wie folgt definiert:
 ,
,
wobei n die Größe der Probe für ein kleines Aggregat ist; N 0 - die Größe der Probe, berechnet nach den obigen Formeln; N ist das Volumen der allgemeinen Bevölkerung.
Natürlich führt die Verwendung kleinerer Proben zu Zeiteinsparungen und Geld.
Die obigen Formeln zur Berechnung der Größe der Probe basieren auf der Annahme, dass alle Probenbildungsregeln beobachtet wurden und der einzige Fehler der Probe aufgrund seines Volumens ein Fehler ist. Es sollte jedoch daran erinnert werden, dass die Größe der Probe die Genauigkeit der erzielten Ergebnisse ermittelt, jedoch nicht ihre Repräsentativität.
Letzteres wird durch das Abtastverfahren bestimmt. Alle Formeln zur Berechnung der Größe der Proben deuten darauf hin, dass die Repräsentativität durch die Verwendung der korrekten probabilistischen Probenahmeverfahren gewährleistet ist.
Das Volumen, die Probe, wird durch die Analyse, Ziele der Studie bestimmt, und seine Repräsentativität ist die Zielinstallation des Programms. Es ist das Programm, das das Bild der notwendigen allgemeinen Bevölkerung für die Probenahme setzt. Ob es sich um die gesamte Bevölkerung oder ihre speziellen Strukturformationen handelt, wobei alle Elemente des Untersuchungsobjekts untersucht oder nur nach dem angegebenen Kriterienprogramm zugewiesen werden, ist die allgemeine Bevölkerung alle im Objektprogramm definierten Einheiten.
Während eines deterministischen Ansatzes für die Probenstruktur ist es im Allgemeinen nicht möglich, dass es möglich ist, das Volumen entsprechend dem angegebenen Kriterium für die Zuverlässigkeit der erhaltenen Informationen genau zu bestimmen. In diesem Fall kann die Größe der Probe empirisch bestimmt werden. Die Tätigkeit der Marketingforschung im Ausland kann als Richtlinie dienen. Bei der Untersuchung von Käufern ist die hohe Genauigkeit der Probe so sicher, dass auch wenn sein Volumen 1% des gesamten Sets bei der Durchführung von Umfragen für Kunden von mittel- und großen Einzelhandelsunternehmen nicht überschreitet, ist die Anzahl der Befragten (Abtastvolumen) in der Regel schwankte von 500 bis 1000 Menschen.
Der Wert des Verfahrens zum Auswählen der Methode zum Sammeln von Primärinformationen, und die Instrumente der Studie ist, dass die Ergebnisse dieser Auswahl sowohl die Zuverlässigkeit als auch die Genauigkeit der zu erzierenden Informationen und der Dauer und den hohen Kosten von Sammlung.
Um die Wahrscheinlichkeiten der Ereignisse zu ermitteln, an denen Sie interessiert sind, verwenden wir die selektive Methode: Wir führen aus n. unabhängige Experimente, in denen jeweils (oder nicht passieren) Ereignis A (Wahrscheinlichkeit) auftreten können r. Das Erscheinungsbild von Ereignissen A in jedem Experiment ist konstant). Dann die relative Frequenz p * Erscheinungen von Ereignissen ABER In der Serie n. Tests werden als Punktschätzung für die Wahrscheinlichkeit akzeptiert. p. Ereignisaussehen. ABER In einem separaten Test. In diesem Fall wird der Wert von p * aufgerufen selektive Anteil Ereignisauftritte ABERund r - allgemeines .
Aufgrund der Untersuchung des zentralen Grenzwerts (der MOOREV-LAPLAPLEOREM) kann die relative Frequenz des Ereignisses mit einer großen Menge an Probenahme normalerweise mit den Parametern M (p *) \u003d P und
Daher kann mit N\u003e 30 das Vertrauensintervall für den allgemeinen Anteil mit Formeln erstellt werden:

wo u kr auf den Tabellen der Laplace-Funktion liegt, unter Berücksichtigung einer bestimmten Vertrauenswahrscheinlichkeit γ: 2f (u Cr) \u003d γ.
Mit einer kleinen Probengröße von n ≤ 30 wird der Fehler & epsi; vom Schülerverteilertabellen bestimmt: ![]() wobei t kr \u003d t (k; α) und die Anzahl der Freiheitsgrade k \u003d n-1 die Wahrscheinlichkeit α \u003d 1-γ (zweiseitiger Bereich).
wobei t kr \u003d t (k; α) und die Anzahl der Freiheitsgrade k \u003d n-1 die Wahrscheinlichkeit α \u003d 1-γ (zweiseitiger Bereich).
Formeln sind gültig, wenn die Auswahl von zufällig wieder (der allgemeine Set von unendlich) durchgeführt wurde, andernfalls ist es notwendig, die Besonderheit der Auswahl (Tabelle) eine Korrektur zu korrigieren.
Durchschnittlicher Abtastfehler für die allgemeine Aktie
| Allgemeines Aggregat | Unendlich | Endliches Volumen N. |
| Auswahltyp. | Wiederholt | Erfassung |
| Durchschnittlicher Probenfehler. |
Formeln zur Berechnung der Größe der Probe mit einer erschwinglichen Auswahlmethode
| Die Auswahlmethode | Probenahme numerische Formeln. | ||
| für Mitte | für einen Anteil | ||
| Wiederholt | |||
| Erfassung | |||
Allgemeine Aufgaben
Die Frage "deckt das Vertrauensintervall des angegebenen Werts P 0 ab?" - Sie können antworten, indem Sie die statistische Hypothese H 0: P \u003d P 0 überprüfen. Es wird angenommen, dass Experimente gemäß Bernoulli-Testschema (unabhängig, Wahrscheinlichkeit) durchgeführt werden p. Ereignisaussehen. ABER Konstante). Durch das Probenvolumen. n. Bestimmen Sie die relative Frequenz von p * das Erscheinungsbild des Ereignisses A: wobei m. - Die Anzahl der Ereignisse ABER In der Serie n. Tests Zur Überprüfung der H 0-Hypothese werden Statistiken verwendet, die eine normale Normalverteilung mit einer ausreichend großen Probe (Tabelle 1) aufweisen.Tabelle 1 - Hypothese über den allgemeinen Anteil
Hypothese | H 0: P \u003d P 0 | H 0: P 1 \u003d P 2 |
| Annahmen | Bernoulli-Testschema. | Bernoulli-Testschema. |
| Probenratings. |  |
|
| Statistiken K. |  |  |
| Statistische Verteilung K. | Standard Normal n (0,1) |
Beispiel Nummer 1. Mit Hilfe einer zufälligen Neuauswahl führte die Verwaltung des Unternehmens eine Musterbefragung von 900 seiner Mitarbeiter durch. Zu den Befragten erwiesen sich als 270 Frauen. Erstellen Sie ein Konfidenzintervall mit einer Wahrscheinlichkeit von 0,95, die den wahren Anteil der Frauen im gesamten Team des Unternehmens abdeckt.
Entscheidung. Durch die Bedingung ist der Musteranteil von Frauen (die relative Häufigkeit von Frauen unter allen Befragten). Da die Auswahl wiederholt wird, und die Größe der Probe ist groß (n \u003d 900) wird der Auswahlfehler durch die Formel bestimmt ![]()
Der Wert von U KR Findet die Tabelle der Laplace-Funktion aus dem Verhältnis 2f (u Cr) \u003d γ, d. H. ![]() Die LAPLAP-Funktion (Anhang 1) erfordert einen Wert von 0,475 bei U KR \u003d 1.96. Daher der Grenzfehler
Die LAPLAP-Funktion (Anhang 1) erfordert einen Wert von 0,475 bei U KR \u003d 1.96. Daher der Grenzfehler ![]() und das gewünschte Konfidenzintervall
und das gewünschte Konfidenzintervall
(P - ε, p + ε) \u003d (0,3 - 0,18; 0,3 + 0,18) \u003d (0,12; 0,48)
Mit einer Wahrscheinlichkeit von 0,95 kann es gewährleistet sein, dass der Anteil der Frauen im gesamten Team des Unternehmens im Bereich von 0,12 bis 0,48 liegt.
Beispiel Nummer 2. Der Besitzer des Parkplatzes liest den Tag "erfolgreich", wenn der Parkplatz mit mehr als 80% gefüllt ist. Während des Jahres wurden 40 Parkpläste durchgeführt, von denen 24 "erfolgreich" waren. Finden Sie mit einer Wahrscheinlichkeit von 0,98 das Konfidenzintervall, um den wahren Anteil an "erfolgreichen" Tagen im Laufe des Jahres zu bewerten.
Entscheidung. Der Musteranteil von "erfolgreichen" Tagen ist
Auf der Tischfunktion des Laplace finden wir den Wert von u Cr mit einem bestimmten
vertrauenswahrscheinlichkeit
F (2.23) \u003d 0,49, U Kr \u003d 2.33.
In Anbetracht der Auswahl ist nicht möglich (d. H. Zwei Schecks wurden an einem Tag nicht durchgeführt), finden wir einen Grenzwertfehler: ![]()
wobei n \u003d 40, n \u003d 365 (Tage). Von hier ![]()
und das Vertrauensintervall für den allgemeinen Anteil: (p - ε, p + ε) \u003d (0,6 - 0,17; 0,6 + 0,17) \u003d (0,43; 0,77)
Mit einer Wahrscheinlichkeit von 0,98 ist zu erwarten, dass der Anteil von "erfolgreichen" Tagen während des Jahres im Bereich von 0,43 bis 0,77 liegt.
Beispielnummer 3. Überprüfen von 2500 Produkten in der Partei, entdeckte, dass 400 Produkte der höchsten Note und N-M-Nr. Wie viel müssen Sie die Produkte überprüfen, um den Anteil der höchsten Note mit Vertrauen von 95% bis 0,01 zu ermitteln?
Lösung Wir suchen die Formel zur Bestimmung der Anzahl der Abtastung zur Neuauswahl.
F (t) \u003d γ / 2 \u003d 0,95 / 2 \u003d 0,475 und dieser Wert auf der Laplace-Tabelle entspricht T \u003d 1,96
Selektive Freigabe W \u003d 0,16; Fehlerprüfung ε \u003d 0,01
Beispiel Nummer 4. Die Charge der Produkte wird akzeptiert, wenn die Wahrscheinlichkeit, dass das Produkt der geeignete Standard sein wird, mindestens 0,97 beträgt. Unter den zufällig ausgewählten 200 Produkten der empfangenen Charge waren 193 relevante Standards. Ist es möglich, auf der Ebene der Bedeutung α \u003d 0,02, um die Partei anzunehmen?
Entscheidung. Wir formulieren die Haupt- und Alternative Hypothese.
H 0: P \u003d P 0 \u003d 0,97 - Unbekannt allgemeine Anteil p. gleich einem bestimmten Wert p 0 \u003d 0,97. In Bezug auf den Zustand - die Wahrscheinlichkeit, dass der Teil der erhaltenen Charge für den Standard relevant ist, gleich 0,97; jene. Eine Charge von Produkten kann genommen werden.
H 1: P<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Der beobachtete Wert der Statistiken K. (Tabelle) Berechnen Sie bei den angegebenen Werten P 0 \u003d 0,97, n \u003d 200, m \u003d 193
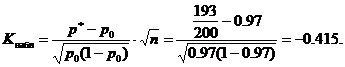
Kritische Bedeutung Finden Sie die Tabelle der Laplace-Funktion von der Gleichheit
![]()
Unter der Bedingung α \u003d 0,02, von hier aus f (kkr) \u003d 0,48 und kkr \u003d 2,05. Kritische Region linksseitig, d. H. Es ist das Intervall (-∞; -k kp) \u003d (-∞; -2.05). Der beobachtete Wert an Navel \u003d -0.415 gehört nicht zum kritischen Bereich, daher gibt es bei dieser Bedeutung, daher gibt es keinen Grund, die Haupthypothese abzulenken. Sie können eine Charge von Produkten nehmen.
Beispiel Nummer 5. Zwei Pflanzen machen die gleichen Art von Details. Um ihre Qualität zu beurteilen, werden Proben aus den Produkten dieser Anlagen hergestellt, und die folgenden Ergebnisse werden erzielt. Unter 200 ausgewählten Produkten der ersten Pflanze erwiesen sich als 20 defekt unter 300 Produkten der zweiten Anlage - 15 defekt.
Auf der Ebene von Bedeutung 0.025 finden Sie heraus, ob es einen signifikanten Unterschied gibt, wenn die von diesen Anlagen hergestellten Teile erheblich sind.
Unter dem Zustand α \u003d 0,025, daher f (ckr) \u003d 0,4875 und kkr \u003d 2.24. Mit einer bilateralen Alternative hat der Bereich der zulässigen Werte das Formular (-2.24; 2.24). Der beobachtete Wert k navel \u003d 2,15 fällt in dieses Intervall, d. H. Bei diesem Maß an Bedeutung gibt es keinen Grund, die Haupthypothese abzulehnen. Pflanzen machen Produkte derselben Qualität.