Pogosto se zgodi, da je treba analizirati kateri koli poseben družbeni pojav in dobiti informacije o njem. Takšne naloge se pogosto pojavljajo v statistiki in statistične študije. Preverite popolnoma določen družbeni pojav, je najpogosteje nemogoče. Na primer, kako ugotoviti mnenje prebivalstva ali vseh prebivalcev določenega mesta na vsakem vprašanju? Vprašajte absolutno vse - primer je skoraj nemogoč in zelo težaven. V takih primerih potrebujemo vzorec. To je točno koncept, na katerem temeljijo skoraj vse raziskave in teste.
Kaj je vzorec
Pri analizi določenega družbenega pojava je potrebno pridobiti informacije o tem. Če vzamete kakršne koli raziskave, potem je mogoče opozoriti, da študija in analiza ne velja vsaka enota niza raziskovalnega predmeta. Upošteva se le določen del celotne celote. Ta proces je vzorec: ko preiskujejo le nekatere enote iz niza.
Seveda je veliko odvisno od vrste vzorčenja. Vendar obstajajo osnovna pravila. Glavna stvar je, da mora biti izbira agregata popolnoma naključna. Enote agregata, ki se bodo uporabljali, se ne smejo izbrati zaradi kakršnega koli merila. V grobem, če morate zbrati celoto prebivalstva določenega mesta in vzeti samo moški, potem bo študija napaka, ker izbir ni bil po nesreči porabljen, vendar je izbral spol. Skoraj vse vzorčne metode temeljijo na tem pravilu.
Izbirna pravila
Da bi izbrani agregat odražal glavne lastnosti celotnega pojava, ga je treba zgraditi v skladu s posebnimi zakoni, kjer se je treba osredotočiti na naslednje kategorije:
- vzorec (selektivni agregat);
- splošno prebivalstvo;
- reprezentativnost;
- reprezentativna napaka;
- skupna enota;
- metode za izgradnjo vzorca.
Lastnosti selektivno opazovanje In vzorec je sestavljen iz:
- Vsi dobljeni rezultati temeljijo na matematičnih zakonih in pravilih, to je z ustreznimi raziskavami in pod pravilnimi izračuni, rezultati ne bodo izkrivljeni na subjektivni osnovi.
- To daje priložnost veliko hitreje in z manj časa in virov, da dobijo rezultat, ne preučuje celotno paleto dogodkov, ampak le njihov del.
- Lahko se uporablja za preučevanje različnih predmetov: od posebnih vprašanj, na primer, starost, nadstropje skupine, ki vas zanimajo, za študijo javno mnenje ali raven materialne podpore prebivalstva.
Selektivno opazovanje
Vzorec - je statistično opazovanjeV kateri študija ni predmet celotnega celotnega študija, ampak le nekaj, izbranih na določen način, in rezultati študije tega dela so razdeljeni na celoten niz. Ta del se imenuje selektivni set. To je edini način, da preučite veliko paleto predmeta študije.
Vendar selektivno opazovanje se lahko uporablja samo v primerih, ko je treba raziskati le majhno skupino enot. Na primer, ko študiramo razmerje med ženskami na svetu, se bo uporabljala selektivna opazovanje. Iz očitnih razlogov je nemogoče upoštevati vsakega rezidenta našega planeta.
Toda z isto študijo, vendar ne vsi prebivalci zemlje, ampak določen 2 "a" razred v določeni šoli, določenem mestu, določeni državi, lahko storijo brez selektivnega opazovanja. Konec koncev, da analiziramo celotno paleto predmeta študije - je povsem mogoče. Treba je izračunati fantje in dekleta tega razreda - to bo razmerje.

Selektivni in splošni agregat
Pravzaprav vse ni tako težko, kot se sliši. V vsakem predmetu študije obstajata dva sistema: splošni in selektivni agregat. Kaj je to? Vse enote se nanašajo na splošno. In selektivno - tiste enote celotnega agregata, ki so bili sprejeti za vzorec. Če je vse opravljeno pravilno, bo izbrani del zmanjšana razporeditev celotnega (splošnega) kompleta.
Če govorimo o splošnem agregatu, se lahko razlikujeta le dve vrsti tega: določen in nedoločen splošni agregat. Odvisno od tega, ali je skupno število enot tega sistema znano ali ne. Če je to določen splošni sklop, bo vzorec lažje zaradi tega, kar je znano, kateri odstotek skupnega števila enot bo vzorec.
Ta trenutek je zelo potreben v raziskavah. Na primer, če morate preučiti odstotek slabih slaščic v določeni tovarni. Recimo, da je splošni agregat že opredeljen. Znano je, da ta družba ta družba proizvaja 1000 slaščic. Če naredite vzorec 100 naključnih slaščic iz tega tisoč in jih pošljete na pregled, bo napaka minimalna. Grobo, študija je bila napisana na 10% vseh proizvodov, na rezultate pa lahko, ob upoštevanju napake reprezentativnosti, govorite o slabi kakovosti vseh izdelkov.
In če imate vzorec 100 slaščic iz nedoločenega splošnega agregata, kjer so bili dejansko, so bili sprejeti, 1 milijon enot, rezultat vzorca in sama raziskava bo kritična in netočna. Čutite razliko? Zato je gotovost splošne populacije v večini primerov izjemno pomembna in močno vpliva na rezultat študije.

Reprezentativnost agregatov
Torej, zdaj eno najpomembnejših vprašanj - kaj bi moral biti vzorec? To je glavni trenutek študije. Na tej stopnji je treba izračunati vzorec in izbrati enote iz skupaj. v. Komplet je bil pravilno izbran, če nekatere značilnosti in značilnosti splošne populacije ostanejo v selektivni. To se imenuje predstavnik.
Z drugimi besedami, če se po izbiri del obdrži enake trende in funkcije, ki jih je celoten znesek preiskanega, nato tak niz se imenuje predstavnik. Vendar pa ne moremo izbrati vsakega posebnega vzorca iz reprezentativne celote. Obstajajo takšni predmeti študije, katerega vzorec preprosto ne more biti reprezentativen. Od tu se pojavi pojem reprezentativnosti. Toda o tem bomo govorili malo več.
Kako narediti vzorec
Torej, da je reprezentativnost maksimum, dodeljuje tri osnovna vzorčna pravila:

Napaka (napaka) reprezentativnost
Glavna značilnost kakovosti izbranega vzorca je koncept "reprezentativne napake". Kaj je to? To so določena neskladja med kazalniki selektivnega in trdnega opazovanja. Kar zadeva napake, je reprezentativnost razdeljena na zanesljivo, navadno in približno. Z drugimi besedami, dovoljena odstopanja v višini do 3%, od 3 do 10% oziroma od 10 do 20%. Čeprav je v statistiki zaželeno, da napaka ne presega 5-6%. V nasprotnem primeru obstaja razlog za pogovor o nezadostni reprezentativnosti vzorca. Za izračun nujnosti reprezentativnosti in kako vpliva na selektivno ali splošno populacijo, se upoštevajo številni dejavniki: \\ t
- Verjetnost, s katero je potrebno pridobiti natančen rezultat.
- Število enot selektivnega agregata. Kot smo že omenili, bo manj enot vzorec, večja bo napaka reprezentativnosti, in obratno.
- Enakomernost celote v študiji. Bolj heterogena je celota, večja je negotovost reprezentativnosti. Možnost agregata, ki je reprezentativna, je odvisna od enotnosti vseh njegovih komponent.
- Način izbora enot selektivni agregat.
V posebnih študijah se odstotek povprečne napake običajno določi sam raziskovalec na podlagi programa opazovanja in v skladu s podatki o predhodno opravljenih študijah. Praviloma se veljavna napaka vzorčenja šteje za dopustno napako (reprezentativnost) v 3-5%.

Več - ne vedno boljše
Prav tako je treba spomniti, da je glavna stvar pri organizaciji selektivnega opazovanja, da se njena količina dopustnega minimalnega. Ne sme si prizadevati za pretirano zmanjšanje meja napake vzorčenja, saj to lahko privede do neupravičenega povečanja velikosti teh vzorcev in zato povečanju izdatkov za selektivno opazovanje.
Hkrati pa je nemogoče preveč povečati velikosti nujnosti reprezentativnosti. V tem primeru, čeprav se bo zmanjšalo količino selektivnega agregata, bo to povzročilo poslabšanje točnosti dobljenih rezultatov.
Kakšna vprašanja se običajno dajejo pred raziskovalcem
Vsaka študija, če se izvede, potem za nekatere rezultate. Pri izvajanju študije vzorčenja se praviloma postavljajo začetna vprašanja: \\ t

Metode za izbiro raziskav v vzorcu
Vsak vzorec ni zastopan. Včasih je isti znak na splošno drugačen na splošno in v svojih delih. Za doseganje zahtev reprezentativnosti je priporočljivo uporabiti različne tehnike vzorčenja. Poleg tega je uporaba ene ali druge metode odvisna od posebnih okoliščin. Med temi tehnikami ustvarjanja vzorcev se razlikujejo:
- naključna izbira;
- mehanska izbira;
- tipična izbira;
- serijska (gnezda).
Naključni izbor je sistem ukrepov, namenjenih naključnem izboru agregatov, ko je verjetnost pridobivanja v vzorec enaka vsem enotam splošne populacije. Priporočljivo je, da to tehniko uporabljate samo v primeru homogenosti in majhnega števila znakov, povezanih z njim. V nasprotnem primeru se ne odražajo nekatere značilne značilnosti, ki se ne odražajo v vzorcu. Znaki naključnega izbora temeljijo na vseh drugih načinih za izgradnjo vzorca.
Z mehanskim izborom enot se izvaja skozi določen interval. Če morate oblikovati vzorec posebnih kaznivih dejanj, lahko umaknete iz vseh statističnih računovodskih kartic registriranih kaznivih dejanj vsakega 5, 10. ali 15. kartice, odvisno od skupnega števila in velikost vzorca. Pomanjkljivost te metode je, da je pred izbiro potrebno imeti popolno računovodstvo agregatov, nato razvrstitev in šele po tem, da je mogoče vzorčiti z določenim intervalom. Ta metoda traja veliko časa, zato se pogosto ne uporablja.

Tipična (coned) izbira je vrsta vzorčenja, v katerem je splošna populacija razdeljena na homogene skupine na določenem znaku. Včasih raziskovalci namesto skupin uporabljajo druge izraze: "Okrožje" in "cone". Potem, iz vsake skupine v naključnem vrstnem redu, je določeno število enot izbran v sorazmerju s posebno težo skupine v skupnem agregatu. Tipična izbira se pogosto izvaja v več fazah.
Serijska izbira je metoda, na kateri izbor enot izvaja skupine (serija) in vse enote izbrane skupine (serije) so predmet ankete. Prednost te metode je, da včasih izberejo posamezne enote bolj zapletene kot serija, na primer, ko študirate osebo, ki služi stavek. V okviru izbranih območij območja uporabljajo študijo vseh enot brez izjeme, na primer študijo vseh oseb, ki služijo kazni v določeni instituciji.
vrste vzorčenja:
Dejansko naključno;
Mehansko;
Značilno;
Serijska;
Kombinirano.
Pravzaprav naključni vzorecizbor enot iz splošnega agregata naključno, brez kakršnih koli elementov sistema. Vendar pa je pred izdelavo samokontrole izbire, je treba zagotoviti, da imajo vse enote splošne populacije popolnoma enake možnosti za pridobivanje v vzorec, ni prehodov, ne upošteva posameznih enot, in podobno. Prav tako bi morala določiti jasne meje splošne populacije, tako da vključitev ali nesklajenost posameznih enot ne povzroča dvomov. Na primer, ko je preučevanje študentov, je treba navesti, ali bodo upoštevane osebe v akademskem dopustu, študente nedržavnih univerz, vojaške šole itd.; Pri preučevanju trgovskih podjetij je pomembno ugotoviti, ali bo splošni agregat vključeval trgovske paviljone, komercialne šotore in druge podobne predmete. Self-naključni izbor se lahko ponavlja in prevratno. Za izvedbo ponudbenega izbora v procesu risanja, divja se sklopi nazaj v prvotni set ne bo vrnjen in v prihodnje se izbor ni vključen. Ko uporabljate tabele naključnih števil, se stopnja intrakcij doseže s prehodom v primeru ponavljanja v izbranem stolpcu ali stolpcih.
Mehanski vzorecuporablja se v primerih, ko je splošna populacija na kakršen koli način naročite, tj. Obstaja določena zaporedja na lokaciji enot (štedilniki zaposlenih, seznami volivcev, številke anketiranih, hiš in apartmajev itd.).
Splošna kombinacija mehanskega izbora se lahko uvrsti ali racionalizira z obsegom znaka ali korelacijo z njo, ki bo povečala reprezentativnost vzorca. V tem primeru pa se tveganje sistematične napake povečuje, povezano z nezadostnim preučevanim atributom (če je prva vrednost evidentirana iz vsakega intervala) ali s svojo precenjevanje (če je zadnja vrednost zabeležena iz vsakega intervala). Zato je priporočljivo začeti od sredine prvega intervala
Tipična izbira.Ta metoda izbire se uporablja v primerih, ko se lahko vse enote splošne populacije razdelijo na več tipičnih skupin. Med pregledom prebivalstva so lahko takšne skupine na primer območja, socialna, starost ali izobraževalne skupine, Med raziskavo podjetij - podružnica ali podmordustrija, oblika lastništva itd. Tipična izbira vključuje vzorec enot iz vsake tipične skupine z naključnim ali mehanskim načinom. Ker so predstavniki vseh skupin v enem ali drugem razmerju, predstavniki vseh skupin, na tak ali drugačen način, se poiskati, tipkanje splošne populacije omogoča odpravo učinka razpršenosti medskupin na povprečno napako vzorčenja, ki v Ta primer določi samo različica znotraj skupine.
Izbor enot v tipičnem vzorcu je mogoče organizirati ali sorazmerno z obsegom tipičnih skupin, ali sorazmerno z razlikovanjem znotraj skupine.
Serijska izbira.Ta metoda izbire je primerna v primerih, ko se enote celote združijo v majhne skupine ali serije. Kot taka serija, pakiranje z določenim številom končnih izdelkov, serija blaga, študentskih skupin, brigade in drugih združenj je mogoče upoštevati. Bistvo serijskega vzorca je v naključnem ali mehanske izbire serije, v kateri je izdelan trden pregled enot.
Empirično veljajo eno od glavnih sredstev za proučevanje družbenih odnosov in procesov. Zagotavljajo zanesljive, popolne in reprezentativne informacije.
Specifičnost tehnik
Empirični prejemanje dejanskega znanja. Prispevajo k vzpostavitvi in \u200b\u200bposploševanju okoliščin na račun posredovane ali neposredne registracije dogodkov, ki so del naučenih odnosov, predmetov, pojavov. Empirične tehnike se razlikujejo od teoretičnega dejstva, da je predmet analize:
- Obnašanja posameznikov in njihovih skupin.
- Človeška dejavnost.
- Verbalne dejavnosti posameznikov, njihovih sodb, pogledov, mnenj.
Vzorčne študije
Empirično učenje je vedno osredotočeno na pridobivanje objektivnih in natančnih informacij, kvantitativnih podatkov. V zvezi s tem, ko je izpolnjeno, je treba zagotoviti reprezentativnost informacij. V skladu s tem je pravilna vrednost pravilna selektivni agregat. to. To pomeni, da je treba izbor izvesti tako, da pridobljeni podatki ozke skupine odražajo trende, ki potekajo v skupni masi anketirancev. Na primer, pri pregledu 200-300, se lahko pridobljeni podatki ekstrapolirajo na vse urban prebivalstvo. Kazalniki selektivnega agregata omogočajo drugačen pristop k študiji socialno-ekonomskih procesov v regiji v državi kot celoti.

Terminologija
Za boljše razumevanje vprašanj, povezanih s selektivnimi raziskavami, je treba pojasniti nekatere opredelitve. Enota opazovanja je neposredni vir informacij. Lahko so ločeni posameznik, skupina, dokument, organizacija, in tako naprej. Splošni agregat je Kompleks opazovalnih enot. Vsi bi morali biti povezani s problemom, ki je preučen. Neposredno analizo. Študija se izvaja v skladu z razvitimi metodami za zbiranje informacij. Za določitev tega deleža celotnega paleta anketirancev koncept "selektivnega agregata". Njegova lastnina odraža ključne parametre skupne mase ljudi se imenuje reprezentativnost. V nekaterih primerih ni naključja. Potem govorijo o napaki reprezentativnosti.
Nudenje reprezentativnosti
Podrobnosti Vprašanja, povezana z njim, se razpravljajo v okviru statistike. Težave se odlikujejo po kompleksnosti, saj se na eni strani predlaga, da se zagotovi kvantitativno predstavitev, ki daje splošno prebivalstvo. to. Označuje zlasti, da morajo biti skupine anketirancev predložene v optimalni številki. Količina mora zadostovati za normalno predstavitev. Po drugi strani pa obstaja tudi kvalitativna predstavitev. Vključuje določeno temo, ki je oblikovana selektivni agregat. to. To pomeni, da na primer, ni mogoče razpravljati o reprezentativnosti, če se razpravljajo samo moški, ali samo ženske, starejši ljudje. Študija je treba izvesti v vseh predstavljenih skupinah.

Značilen vzorec
Ta izraz se obravnava v dveh vidikih. Najprej je opredeljen kot kompleks elementov iz skupnega paleta ljudi, katerih mnenje se preučuje - to selektivni agregat. to. Tudi proces ustvarjanja določene kategorije anketirancev z zahtevano zagotavljanjem reprezentativnosti. V praksi je več vrst in vrst izbire izstopajo. Razmislite o njih.
Vrste
Obstajajo trije:
- Spontano selektivni agregat. to. Niz anketirancev, izbranih na načelu prostovoljnosti. Hkrati je zagotovljena razpoložljivost enot iz skupne mase ljudi v določeno študijsko skupino. Spontana izbira v praksi se pogosto uporablja. Na primer, z anketami v tisku, po pošti. Vendar pa ima ta tehnika pomembna pomanjkljivost. Celoten znesek splošnega vzorca ni mogoče kvalitativno predstaviti. Ta tehnika se uporablja na podlagi gospodarstva. V nekaterih anketah je ta možnost edina možna.
- Spontano selektivni agregat. to. Ena od glavnih tehnik, ki se uporabljajo v študiji. Kot ključno načelo take izbire je mogoče zagotoviti priložnosti za vsako opazovalno enoto, da bi dobili od skupne mase posameznikov v ozko skupino. To uporablja različne tehnike. Na primer, lahko je loterija, mehanska izbira, tabela naključnih števil.
- Stratificirani (quarry) vzorec. Temelji na oblikovanju kvalitativnega modela skupne mase anketirancev. Po tem se izbor enot izvede v selektivni celovitvi. Na primer, opraviti se po starosti ali spolu, po prebivalstvu in tako naprej.
Ogledi
Obstajajo naslednji vzorci:

Dodatno
Vzorci so lahko odvisni tudi in neodvisni. V prvem primeru, eksperimentalni postopek in rezultati, ki bodo pridobljeni za eno skupino anketirancev, med njim imajo določen vpliv na drugo. Zato neodvisni vzorci ne nameravajo takšnega vpliva. Vendar pa morate paziti na eno pomembno točko. Ena skupina subjektov, za katero je bila izvedena psihološka preiskava (tudi če je bila namenjena preučevanju različnih lastnosti, funkcij, funkcij), se privzeto šteje za odvisna.
Probabilistične izbire
Razmislite o nekaterih vrstah vzorcev:
- Naključen. Vključuje homogenost skupnega agregata, ena verjetnost razpoložljivosti vseh komponent, kot tudi prisotnost celotnega seznama elementov. Praviloma se med izborom uporablja tabela z naključnimi številkami.
- Mehansko. Ta vrsta naključnega vzorčenja pomeni naročanje na določeno funkcijo. Na primer, po telefonski številki, po abecednem vrstnem redu, po datumu rojstva in tako naprej. Prva komponenta je izbrana v naključnem vrstnem redu. Nato se izbor vsakega elementa K s korakom n. Velikost celotnega agregata bo n \u003d K * n.
- Straktično. Ta vzorec se uporablja pri nehomogenosti celotnega agregata. Slednji je razdeljen na Strata (skupine). V vsakem od njih se izbor izvede z mehanskim ali naključnim načinom.
- Serijska. Izbira skupine je naključno. V njih se predmeti preučujejo s trdno snovjo.
Neverjetne izbire
Predlagajo vzorec, ki ni na načelu možnosti, vendar po subjektivnih znakih: tipična, dostopnost, enaka zastopanost in tako naprej. Ta kategorija vključuje izbire:

Nianse.
Zagotoviti reprezentativnost, natančen in popoln seznam agregatov. Predmeti opazovanja, praviloma, je ena oseba. Izbor s seznama je bolje izvesti, številčne enote in nanašati tabelo z naključnimi številkami. Toda metoda Quasonion se pogosto uporablja pogosto. To pomeni izbor s seznama vsakega elementa N.
Vplivajo na dejavnike
Obseg agregata se imenuje številka njegovih enot. Po mnenju strokovnjakov, ne je treba biti velik. Nedvomno, več Anketiranci, natančnejši rezultat. Vendar pa skupaj z njim velik znesek ne zagotavlja vedno uspeha. Na primer, to se zgodi, ko je celotno paleto anketirancev neenakomerno. Homogena se bo štela za takšno kombinacijo, kjer je nadzorni parameter, na primer, stopnja pismenosti enakomerno porazdeljena, to je, da ni praznine ali zgoščevanja. V tem primeru bo dovolj za razgovor z več ljudmi. Po rezultatih ankete bo mogoče sklepati, da ima večina ljudi normalno stopnjo pismenosti. Iz tega izhaja, da vpliv informacij ni kvantitativni znaki, vendar so kvalitativne značilnosti agregata enaka njegove homogenosti, zlasti.

Napake
Predstavljajo odstopanje povprečnih parametrov vzorca na vrednosti skupne mase anketirancev. V praksi se napake določijo v primerjavi. Med pregledom odraslih veljajo korespondenca, statistično računovodstvo, kot tudi rezultate preteklih raziskav. Parametri krmiljenja običajno izvedejo primerjavo povprečnih sklopov agregatov (splošnih in selektivnih), opredelitev po tej napaki in zmanjšanje tega odklona se imenuje reprezentativnost.
sklepe
Selektivna študija je metoda za zbiranje podatkov o napravah in obnašanju ljudi z raziskavo posebej izbranih skupin anketirancev. Ta sprejem se šteje za zanesljivo in ekonomično, čeprav zahteva nekatere tehnike. Osnova je selektivni sklop. Deluje kot določen delež skupne mase ljudi. Izbor se izvede z uporabo posebnih tehnik in je namenjen pridobivanju informacij o celotnem celotnem celotnem času. Slednje, nato pa predstavljajo vse možne javne predmete ali skupino, ki bo preučevana. Pogosto je splošni agregat tako velik, da bo raziskava vsakega predstavnika precej draga in obremenjujoči proces. Zato se uporabi njegov zmanjšan model. V selektivnem nizu so vključeni vsi tisti, ki prejemajo vprašalnike, ki se imenujejo anketiranci, ki dejansko deluje kot predmet študija. Preprosto povedano, predstavlja veliko ljudi, ki so anketirani.

Zaključek
Cilji raziskave so določeni s posebnimi kategorijami, vključenimi v splošno prebivalstvo. Kar zadeva določen delež skupne mase ljudi, je predmet subjektov, ki so vključeni v skupine s pomočjo matematičnih izračunov. Za izbor enot je potreben opis predmeta prvotnega niza. Po določitvi števila subjektov se določi sprejem ali način oblikovanja skupin. Rezultati ankete bodo omogočili opis preučevanega znaka glede vseh predstavnikov skupne mase ljudi. Kot kaže praksa, se selektivna in ne trdne študije izvajajo.
Postopek za pripravo vzorčnega načrta vključuje Zaporedna rešitev treh naslednjih nalog:
Določitev predmeta študije;
Določitev strukture vzorčenja;
Določanje vzorčenja.
Običajno, raziskave objekta To je kombinacija opazovalnih predmetov, ki jih lahko igrajo potrošniki, zaposleni v podjetju, posredniki itd. Če je ta celost tako majhna, da ima raziskovalna ekipa potrebne delovne, finančne in začasne zmogljivosti za vzpostavitev stika z vsakim od svojih elementov, je precej realistična, da izvede neprekinjeno študijo celotnega prebivalstva. V tem primeru z opredelitvijo predmeta študije lahko nadaljujete z naslednjim postopkom (izbira metode zbiranja podatkov, instrument raziskav in način komunikacije z občinstvom).
Vendar pa v praksi zelo pogosto ni mogoče ali primerno, da se nenehna študija celotne populacije. Če želite to narediti, lahko obstajajo naslednji razlogi:
Nezmožnost vzpostavitve stika z nekaterimi elementi celote;
Nerazumno velike stroške vodenja trdne študije ali razpoložljivosti finančnih omejitev, ki ne omogočajo trdnih raziskav;
Predlagane roke, dodeljene za raziskave zaradi izgube z ustreznostjo informacij ali drugih razlogov in ne dopuščajo zbiranju, sistematizaciji in analizi obsežnih podatkov za celotno celotno celotno.
Zato, veliki in razpršeni agregati pogosto preučevamo z vzorčenjem, pod katerimi, kot je dobro znano, se del agregata razume, da pooseblja celoto kot celoto.
Natančnost, s katero vzorec odraža celotno kot celoto, je odvisno strukture in velikost vzorčenja.
Razlikovati dva pristopa k strukturi vzorčenja - Probabilistična in deterministična.
Probabilistični pristop k strukturi vzorčenja Predpostavlja, da se lahko vsak element agregata izbere z določeno verjetnostjo (ne nič). Obstajajo različne vrste Vzorci, ki temeljijo na teoriji verjetnosti (tipične, gnezdenja itd.). Najlažji in pogosti v praksi je preprost naključni vzorec, v katerem ima vsak element agregata enaka izbiro za študijo.
Probabilistični vzorec je bolj natančen, omogoča raziskovalcu, da oceni stopnjo zanesljivosti podatkov, ki jih zbira, čeprav je težje in dražje od determinističnega.
Deterministični pristop na vzorčno strukturo Predpostavlja, da je izbira elementov niza narejena z metodami, ki temeljijo na ugodnostih o ugodnostih, ali na rešitvi raziskovalca ali na pogojnih skupinah.
za udobjeSestavljen je iz izbire vseh elementov agregata, ki temelji na enostavnosti stika s stikom z njimi. Nepopolnost te metode je posledica nizke reprezentativnosti pridobljenega vzorca, ker Udobni elementi agregata za raziskovalca morda niso dovolj značilni predstavniki agregata zaradi ne-naključne in nerazumne izbire.
Po drugi strani pa se je preprostost, učinkovitost in učinkovitost študije, ki jih izvaja ta metoda, pridobila precej razširjeno v praksi in predvsem pri izvajanju predhodnih študij, namenjenih pojasnitvi večjih težav.
Na podlagi metode oblikovanja vzorčenja o odločitvi raziskovalcaSestavljen je iz izbire elementov agregata, ki so po njegovem mnenju njegovi značilni predstavniki. Ta metoda je bolj popolna od prejšnjega, saj temelji na orientaciji na značilnih predstavnikih tartuicije v študiju, čeprav je izbrana na podlagi subjektivnih predstavitev raziskovalcev o tem.
Način vzorčenja na podlagi pogojne standardeSestavljen je iz izbire značilnih elementov agregata v skladu z značilnostmi agregata, pridobljenega prej. Te značilnosti se lahko pridobijo z izvajanjem predhodnih študij in v nasprotju s prejšnjo metodo, ne nosijo subjektivne narave. Zato je ta metoda bolj popolna, vam omogoča, da pridobijo selektivne sklope, ki niso manj reprezentativni od verjetnostnih vzorcev z bistveno manj nadzorovanih stroškov.
Izbira vzorčne strukture (pristop k njegovi tvorbi, vrsta verjetnostne ali kotalne tvorbe determinističnega vzorca), bo raziskovalec moral določiti obseg, tj. Število elementov selektivnega agregata.
Volumen vzorčenja Določa natančnost informacijzaradi njenih raziskav, kot tudi stroške, potrebne za izvajanje raziskav. Velikost vzorca je odvisna Iz stopnje homogenosti ali sort predmetov, ki jih je študiral.
Večja je velikost vzorca, višja je njena natančnost in več stroškov za njeno raziskavo. Z verjetnostnim pristopom k strukturi vzorčenja se lahko njegov obseg določi z uporabo znanih statističnih formul, ki temeljijo na določenih zahtevah za točnost.
V praksi se za opredelitev vzorčenja uporablja več pristopov:
1. Poljuben pristop Na podlagi uporabe "pravil palca". Na primer, ni nujno, da mora biti vzorec 5% celote, da bi dobili natančne rezultate. Ta pristop je preprost in enostaven za izvedbo, vendar ni mogoče ugotoviti natančnosti dobljenih rezultatov. Z dovolj velikim celotnim je lahko tudi zelo draga.
Velikost vzorca se lahko določi na podlagi nekaterih vnaprej določenih pogojev. Na primer, kupec marketinških raziskav ve, da je pri proučevanju javnega mnenja, vzorec običajno 1000-1200 ljudi, zato priporoča raziskovalcu, da se drži te številke. V primeru, da so letne študije na nek na trgu, potem v vsakem letu uporablja vzorec istega volumna. Za razliko od prvega pristopa se tukaj uporablja dobro znana logika pri določanju obsega vzorca, ki je zelo ranljiva.
Na primer, pri izvajanju določenih študij se lahko zahteva natančnost manj kot pri proučevanju javnega mnenja, in skupno celotno je lahko večkrat manj kot pri preučevanju javnega mnenja. Zato ta pristop ne upošteva trenutnih okoliščin in je lahko precej drag.
V nekaterih primerih, kot glavni argument, pri določanju obsega vzorca, se uporabijo stroški ankete. Proračun tržnih raziskav torej predvideva nekatere raziskave, ki jih ni mogoče preseči. Očitno se vrednost prejetih informacij ne upošteva. Vendar pa lahko v nekaterih primerih majhen vzorec daje precej natančne rezultate.
Zdi se, da je smiselno upoštevati stroške, ki niso absolutno, ampak v zvezi z uporabnostjo informacij, pridobljenih kot posledica opravljenih raziskav. Stranka in raziskovalka bi morala obravnavati različne količine vzorcev in metode zbiranja podatkov, stroški, upoštevati druge dejavnike
2. velikost vzorca na ravni zaupnega intervala veljavne napake, \\ t Kar, kot je bilo že omenjeno, je podana s primernostjo natančnosti končnih posplošitev: od povečane do približnega. Vendar pa obstajajo v mislih tako imenovanih naključnih napak, povezanih z naravo vseh statističnih napak. Izračunane so kot napake reprezentativnosti verjetnostnih vzorcev.
V.I. Paniotto navaja naslednje izračune reprezentativnega vzorca z dovoljenji za 5-odstotno napako (tabela 4.2).
Tabela 4.2.
Izračunana vzorčna tabela
Za kombinacijo več kot 100.000 vzorcev je 400 enot. Če upoštevam splošni sklop števila od 5 tisoč in več, potem, glede na izračune istega avtorja, lahko določite vrednosti dejanske napake v vzorcu, odvisno od njene količine, ki je zelo Pomembno je za nas, se spomnim, da je vrednost veljavne napake odvisna od namena raziskav in neobvezna bi morala približati 5-odstotni ravni.
Tabela 4.3.
Izračunana miza
|
Vzorčenje, če je splošni agregat 5000 | ||||||||
|
Dejanska napaka v tem obsegu vzorca,% |
Poleg naključnih, sistematičnih napak so možne. Odvisni so od organizacije selektivnega izpita. To so različni odmik vzorčenja proti eni od nalepk selektivnega parametra.
3. Vzorčenje na podlagi statistične analize . Ta pristop temelji na določanju minimalnega vzorčenja, ki temelji na določenih zahtevah za zanesljivost in zanesljivost dobljenih rezultatov. Uporablja se tudi pri analizi rezultatov, dobljenih za posamezne podskupine, ki so sestavljene kot del izbire na tleh, starosti, stopnji izobrazbe itd. Zahteve za zanesljivost in točnost rezultatov za posamezne podskupine narekujejo določene zahteve za velikost vzorca kot celote.
Najbolj teoretično utemeljen in pravilen pristop k določanju obsega vzorca temelji na izračunu zanesljivih intervalov. Koncept variacije označuje obseg nepravilnih (podobnih) odgovorov anketirancev na določeno vprašanje. V strožjega načrta se različica vrednosti vsakega znaka v določenem nizu imenuje razlika v vrednosti iz različnih enot tega kompleta v istem obdobju ali času. Odgovori za anketna vprašanja so običajno zastopani v obliki krivulje distribucije (slika 4.1). Z visoko podobnostjo, odgovori govorijo o nizkih nihanjih (ozko distribucijsko krivuljo) in z nizko podobnost podobnosti - o visokih variacijah (široka distribucijska krivulja).
Kot merilo variacije se običajno vzame povprečno kvadratno odstopanje, ki je značilno povprečno razdaljo od povprečne ocene odgovorov vsake anketirance z določenim vprašanjem.
Majhna variacija
Visoka variacija
Sl. 4.1. Različne in distribucijske krivulje
Ker so vse tržne rešitve sprejete v negotovosti, je priporočljivo, da se upošteva pri določanju velikosti vzorca. Ker se opredelitev preučenih vrednosti za niz v ozki izvede na podlagi selektivnih statističnih podatkov, je treba določiti obseg (interval zaupanja), ki naj bi bil ocenjen na celoto kot celoto, in napake njihove opredelitve.
Interval zaupanja je obseg, katerih skrajne točke ustreza določenemu odstotku določenih odgovorov na nekaj vprašanj. Interval zaupanja je tesno povezan s povprečnim kvadratnim odstopanjem preučevanega atributa v splošni populaciji: bolj, bolj širši interval zaupanja bi moral biti, da se vključi določen odstotek odgovorov.
Interval zaupanja, enak ali 95% ali 99%, je standard pri izvajanju tržnih raziskav. Noben podjetje ne vodi trženjskih raziskav z oblikovanjem več vzorcev. In matematična statistika omogoča, da pridobijo nekaj informacij o selektivni distribuciji, ki imajo samo podatke o variacijah enega samega vzorca.
Kazalec ocenjevanja vrednotenja, res za celoto kot celoto, od ocene, ki se pričakuje, da je tipičen vzorec, je srednje kvadratna napaka. Poleg tega je več vzorčenja, manjša napaka. Visoka vrednost variacije določa visoko vrednost napake in obratno.
Kadar obstajata samo dve možnosti za dodeljeno vprašanje, izraženo kot odstotek (uporabljen odstotek ukrepa), velikost vzorca se določi z naslednjo formulo: \\ t

kjer je n velikost vzorca; Z je normalizirano odstopanje, določeno na podlagi izbrane ravni zaupanja; P - ugotovljeno variacijo za vzorčenje; G - (100-p); E - dopustna napaka.
Pri določanju kazalnika variacije za določen niz, najprej je priporočljivo, da izvedete predhodno kvalitativno analizo študije zgorevanja, najprej ugotavlja podobnost agregatov v demografskih, družbenih in drugih odnosih zanimanje za raziskovalca. Možno je izvesti pilotno študijo, uporabo rezultatov takšnih študij, ki se izvajajo v preteklosti. Pri uporabi odstotka variabilnosti se upošteva, da je največja variabilnost dosežena za p \u003d 50%, kar je najslabši primer. Poleg tega ta kazalnik radikalno ne vpliva na velikost vzorca. Upoštevano je tudi mnenje o raziskovanju stranke o obsegu vzorčenja.
Velikost vzorca je mogoče opredeliti na podlagi uporabe povprečnih vrednosti in ne odstotnih vrednosti.

kjer je S sekundarno kvadratno odstopanje.
V praksi, če se vzorec oblikuje na novo in podobne raziskave niso bile izvedene, potem S ni znano. V tem primeru je priporočljivo določiti napako E v frakcijah standardnega odstopanja. Izračunana formula se pretvori in pridobi naslednji obrazec:
 kje
kje  .
.
Nad je bil pogovor o agregatih zelo velikih velikosti. Vendar pa v nekaterih primerih agregat ni velik. Običajno, če je vzorec manjši od pet odstotkov agregata, se šteje, da je velik agregat, in izračuni se izvajajo v skladu z zgoraj navedenimi pravili. Če velikost vzorca presega 5% agregata, se slednji šteje za majhno, zgornja formula pa je uvedena s korekcijskim koeficientom.
Velikost vzorca v tem primeru je opredeljena na naslednji način:
 ,
,
kjer je n velikost vzorca za majhen agregat; N 0 - Velikost vzorca, izračunanega v skladu z zgornjimi formulami; N je obseg splošne populacije.
Očitno bo uporaba manjših vzorcev privedla do prihrankov časa in denarja.
Zgornje formule za izračun velikosti vzorca temeljijo na predpostavki, da so bila upoštevana vsa pravila za oblikovanje vzorcev in edina napaka vzorca je napaka zaradi njegovega volumna. Vendar pa je treba spomniti, da velikost vzorca določa točnost dobljenih rezultatov, ne pa njihova reprezentativnost.
Slednji je določen z metodo vzorčenja. Vse formule za izračun velikosti vzorcev kažejo, da je reprezentativnost zagotovljena z uporabo pravilnih možgabilnih postopkov vzorčenja.
Obseg, vzorec je določen z analitičnimi, cilji študije in njena reprezentativnost je ciljna namestitev programa. To je program, ki določa podobo potrebne splošne populacije za vzorčenje. Ne glede na to, ali bo vse prebivalstvo ali njene posebne strukturne formacije, vse elemente preučevanja predmeta, ki se preučujejo ali so dodeljeni po določenem programu meril, je splošna populacija vse enote, opredeljene v programu objekta.
Med determinističnim pristopom do vzorčne strukture na splošno ni mogoče, da je mogoče natančno določiti njen obseg v skladu z določenim merilom za zanesljivost prejetih informacij. V tem primeru se lahko velikost vzorca določi empirično. Dejavnost tržnih raziskav v tujini lahko služi kot smernica. Torej, ko je preučevanje kupcev zagotovljena visoka natančnost vzorca, tudi če njegov obseg ne presega 1% celotnega sklopa, ko izvajajo ankete za kupce srednje in velikih maloprodajnih podjetij, je običajno število anketirancev (obseg vzorčenja) običajno niha od 500 do 1000 ljudi.
Vrednost postopka za izbiro načina zbiranja primarne informacije in instrumentov študije je, da so rezultati te izbire opredeljeni tako zanesljivost in točnost informacij, ki jih je treba pridobiti, in trajanje, ter visoke stroške njene Zbiranje.
Za določitev verjetnosti dogodkov, ki jih zanima, uporabljamo selektivno metodo: izvajamo n. neodvisni eksperimenti, v vsakem primeru se lahko pojavijo (ali ne veljajo) dogodek a (verjetnost r. Videz dogodkov A v vsakem poskusu je konstanten). Potem relativno frekvenco p * nastopi dogodkov Zvezek V seriji n. Preskusi so sprejete kot točkovna ocena verjetnosti. str. Videz dogodka Zvezek V ločenem preskusu. V tem primeru se imenuje vrednost P * selektivni delež Dogodkov Zvezek, in r - general. .
Na podlagi preiskave iz Centralnega mejnega izreka (Moorev-Laplace Therem) se lahko relativna frekvenca dogodka z veliko količino vzorčenja šteje za normalno porazdeljeno s parametri M (P *) \u003d P in
Zato se z N\u003e 30 lahko interval zaupanja za splošni delež zgradi z uporabo formul:

kjer Kr se nahaja na tabelah funkcije Laplace, ob upoštevanju določene verjetnosti zaupanja γ: 2f (u Cr) \u003d γ.
Z majhno velikostjo vzorca n≤30, je napaka ε določena s tabelo distribucije študentov: ![]() kjer je t kr \u003d t (k; α) in število stopenj svobode K \u003d n-1 verjetnost α \u003d 1-γ (dvostranska regija).
kjer je t kr \u003d t (k; α) in število stopenj svobode K \u003d n-1 verjetnost α \u003d 1-γ (dvostranska regija).
Formule veljajo, če je bila izbira izvedena z naključno (splošni niz neskončnih), sicer je treba popraviti posebnost izbire (tabela).
Povprečna napaka vzorčenja za splošni delež
| Splošno agregat | Infinite. | Končni volumen N. |
| Vrsta izbire | Ponovil | Capture. |
| Povprečna napaka vzorca |
Formule za izračun velikosti vzorca s cenovno ugodno metodo izbire
| Metoda izbire | Vzorčenje numeričnih formul. | ||
| za sredino | za delnico | ||
| Ponovil | |||
| Capture. | |||
Splošne naloge
Vprašanje "pokriva interval zaupanja določene vrednosti P 0?" - Lahko odgovorite s preverjanjem statistične hipoteze H 0: P \u003d P 0. Predvideva se, da se eksperimenti izvajajo v skladu z Bernoulli testno shemo (neodvisno, verjetnost str. Videz dogodka Zvezek stalno). Z vzorcem n. Določite relativno frekvenco P * videz dogodka A: kje m. - število dogodkov Zvezek V seriji n. Preskusi. Če želite preveriti hipotezo H 0, se uporabljajo statistični podatki, ki imajo standardno normalno porazdelitev z dovolj velikim vzorcem (tabela 1).Tabela 1 - Hipoteza o splošnem razmerju
Hipoteza | H 0: P \u003d P 0 | H 0: P 1 \u003d P 2 |
| Predpostavke | Bernoulli Test Shema. | Bernoulli Test Shema. |
| Ocene vzorca |  |
|
| Statistika K. |  |  |
| Statistična distribucija K. | Standardna normalna n (0,1) |
Primer številka 1. S pomočjo naključnega ponovnega izbora je vodstvo družbe opravilo vzorčno raziskavo 900 zaposlenih. Med anketiranci so se izkazalo za 270 žensk. Zgradite interval zaupanja, z verjetnostjo 0,95, ki pokriva pravi del žensk v celotni ekipi podjetja.
Sklep. Po pogodbi je vzorec žensk (relativna frekvenca žensk med vsemi anketiranci). Ker se izbor ponovi, in velikost vzorca je velika (n \u003d 900) izbirna napaka se določi s formulo ![]()
Vrednost U KR Poiščite tabelo funkcije Laplace iz razmerja 2F (U CR) \u003d γ, t.j. ![]() Funkcija LAPLACE (Dodatek 1) ima vrednost 0,475 na U kr \u003d 1.96. Zato je napaka
Funkcija LAPLACE (Dodatek 1) ima vrednost 0,475 na U kr \u003d 1.96. Zato je napaka ![]() in želeni interval zaupanja
in želeni interval zaupanja
(P - ε, p + ε) \u003d (0,3 - 0,18; 0,3 + 0,18) \u003d (0,12; 0,48)
Torej, z verjetnostjo 0,95, je mogoče zagotoviti, da je delež žensk v celotni ekipi podjetja v območju od 0,12 do 0,48.
Primer številka 2. Lastnik parkirišča bere dan "uspešen", če je parkirišče napolnjeno z več kot 80%. Med letom je bilo izvedenih 40 parkirnih pregledov, od katerih je bilo 24 "uspešno". Z verjetnostjo 0,98, poiščite interval zaupanja za oceno pravega deleža "uspešnih" dni med letom.
Sklep. Delež vzorca "uspešnih" dni je
Na funkciji tabele na Laplaceu, bomo našli vrednost u Cr z dano
verjetnost zaupanja
F (2.23) \u003d 0,49, u kr \u003d 2.33.
Glede na izbiro ni mogoče (t.j., dva čeka ni bila izvedena v enem dnevu), najdemo mejno napako: ![]()
kjer je n \u003d 40, n \u003d 365 (dni). Od tod ![]()
in interval zaupanja za splošni delež: (p - ε, p + ε) \u003d (0,6 - 0,17; 0,6 + 0,17) \u003d (0,43; 0,77)
Z verjetnostjo 0,98 se lahko pričakuje, da je delež "uspešnih" dni med letom v območju od 0,43 do 0,77.
Primer številka 3. Preverjanje 2500 izdelkov na zabavi, odkrili, da 400 izdelkov najvišjega razreda, in N-M - št. Koliko morate preveriti proizvode, da določimo delež najvišjega razreda z zaupanjem v višini 95% do 0,01?
Rešitev Iščemo formulo za določanje števila vzorčenja za ponovno izbiro.
F (t) \u003d γ / 2 \u003d 0,95 / 2 \u003d 0,475 in ta vrednost na tabeli Laplace ustreza t \u003d 1.96
Selektivni delež w \u003d 0,16; Vzorčenje napak ε \u003d 0,01
Primer 4. Serija izdelkov je sprejeta, če je verjetnost, da bo izdelek ustrezen standard, je vsaj 0,97. Med naključno izbranimi 200 produkti prejetih serij je bilo 193 ustreznih standardov. Ali je mogoče na ravni pomembnosti α \u003d 0,02 sprejeti stranko?
Sklep. Oblikovamo glavno in alternativno hipotezo.
H 0: P \u003d P 0 \u003d 0,97 - Neznan splošni delež str. enaka določeni vrednosti p 0 \u003d 0,97. V zvezi s pogojem - verjetnost, da bo del iz prejetih serij pomemben za standard, enak 0,97; ti. Serije izdelkov je mogoče sprejeti.
H 1: P<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Opazovana vrednost statistike K. (Tabela) izračunajte na določenih vrednostih p 0 \u003d 0,97, n \u003d 200, m \u003d 193
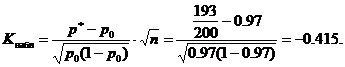
Kritični pomen najdejo tabelo funkcije LAPLACE iz enakosti
![]()
Pod pogojem α \u003d 0.02, od tu F (KKR) \u003d 0,48 in KKR \u003d 2.05. Kritična regija levo stranski, tj. To je interval (-∞; -K kp) \u003d (-∞; -2,05). Opažena vrednost po popku \u003d -0.415 ne pripada kritičnemu območju, zato na tej ravni ni razloga, da bi odklonila glavne hipoteze. Lahko vzamete serijo izdelkov.
Primer 5. Dve rastline naredita enako vrsto podrobnosti. Da bi ocenili njihovo kakovost, so vzorci izdelani iz proizvodov teh rastlin, naslednji rezultati pa se pridobijo. Med 200 izbranimi izdelki prve rastline se je izkazalo za 20 pomanjkljivo, med 300 izdelki druge rastline - 15 okvare.
Na ravni pomembnosti 0,025, ugotoviti, ali obstaja velika razlika kot deli, ki jih proizvajajo te rastline.
Pod pogojem α \u003d 0,025, torej f (CKR) \u003d 0,4875 in KKR \u003d 2.24. Z dvostransko alternativo ima območje dovoljenih vrednosti (-2,24; 2.24). Opažena vrednost K povod \u003d 2,15 spada v ta interval, tj. Na tej ravni ni razloga za zavrnitev glavne hipoteze. Rastline naredijo izdelke iste kakovosti.