Sering terjadi bahwa perlu untuk menganalisis fenomena sosial tertentu dan mendapatkan informasi tentang itu. Tugas-tugas seperti itu sering terjadi dalam statistik dan studi Statistik. Periksa fenomena sosial sepenuhnya tertentu paling sering tidak mungkin. Misalnya, bagaimana cara mengetahui pendapat populasi atau semua penghuni kota tertentu dalam pertanyaan apa pun? Tanyakan semua - kasus ini hampir mustahil dan sangat melelahkan. Dalam kasus seperti itu, kita perlu sampel. Ini persis konsep di mana hampir semua penelitian dan tes didasarkan.
Apa itu sampel
Ketika menganalisis fenomena sosial tertentu, perlu untuk mendapatkan informasi tentang itu. Jika Anda mengambil penelitian apa pun, maka dapat dicatat bahwa studi dan analisis dikenakan tidak setiap unit dari seperangkat objek penelitian. Hanya bagian tertentu dari seluruh totalitas yang diperhitungkan. Proses ini adalah sampel: Ketika hanya unit tertentu dari set yang diselidiki.
Tentu saja, banyak tergantung pada jenis sampling. Tetapi ada aturan dasar. Yang utama adalah bahwa pemilihan agregat harus benar-benar acak. Unit agregat yang akan digunakan tidak boleh dipilih karena kriteria apa pun. Secara kasar, jika Anda perlu mengumpulkan totalitas populasi kota tertentu dan ambil hanya laki-laki, maka penelitian akan menjadi kesalahan, karena pemilihan tidak sengaja dihabiskan, tetapi dipilih oleh gender. Hampir semua metode sampel didasarkan pada aturan ini.
Aturan seleksi
Agar agregat yang dipilih untuk mencerminkan kualitas utama seluruh fenomena, itu harus dibangun sesuai dengan undang-undang tertentu, di mana perlu untuk fokus pada kategori berikut:
- sampel (agregat selektif);
- populasi umum;
- representatif;
- kesalahan representatif;
- unit agregat;
- metode untuk membangun sampel.
fitur pengamatan selektif Dan sampel terdiri dari:
- Semua hasil yang diperoleh didasarkan pada undang-undang dan aturan matematika, yaitu, dengan penelitian yang tepat dan di bawah perhitungan yang benar, hasilnya tidak akan terdistorsi secara subjektif.
- Ini memberi kesempatan jauh lebih cepat dan dengan lebih sedikit waktu dan sumber daya untuk mendapatkan hasilnya, mempelajari bukan seluruh arus acara, tetapi hanya bagian mereka.
- Ini dapat diterapkan untuk mempelajari berbagai objek: dari masalah tertentu, misalnya, usia, lantai grup yang Anda minati, untuk penelitian ini opini publik atau tingkat dukungan material dari populasi.
Pengamatan selektif
Sampel - itu pengamatan statistikDi mana penelitian ini tidak tunduk pada seluruh totalitas belajar, tetapi hanya beberapa, yang dipilih dengan cara tertentu bagiannya, dan hasil penelitian bagian ini didistribusikan ke seluruh set. Bagian ini disebut set selektif. Ini adalah satu-satunya cara untuk mempelajari berbagai objek penelitian.
Tetapi pengamatan selektif hanya dapat digunakan dalam kasus-kasus di mana perlu untuk menyelidiki hanya sekelompok kecil unit. Misalnya, ketika mempelajari rasio pria untuk wanita di dunia, observasi selektif akan digunakan. Untuk alasan yang jelas, tidak mungkin untuk memperhitungkan setiap warga planet kita.
Tetapi dengan penelitian yang sama, tetapi tidak semua penghuni bumi, tetapi kelas 2 "A" di sekolah tertentu, kota tertentu, negara tertentu, dapat dilakukan tanpa pengamatan selektif. Lagi pula, untuk menganalisis seluruh array dari objek penelitian - sangat mungkin. Perlu untuk menghitung anak laki-laki dan perempuan dari kelas ini - yang akan menjadi rasionya.

Agregat Selektif dan Umum
Bahkan, semuanya tidak begitu sulit, seperti kedengarannya. Dalam objek studi apa pun, ada dua sistem: agregat umum dan selektif. Apa itu? Semua unit merujuk pada Jenderal. Dan untuk selektif - unit-unit dari total agregat yang diambil untuk sampel. Jika semuanya dilakukan dengan benar, maka bagian yang dipilih akan menjadi tata letak keseluruhan (umum) yang dikurangi.
Jika kita berbicara tentang agregat umum, maka hanya dua jenis yang dapat dibedakan: agregat umum tertentu dan tidak terbatas. Itu tergantung pada apakah jumlah total unit sistem ini diketahui atau tidak. Jika ini adalah set umum tertentu, maka sampel akan lebih mudah karena apa yang diketahui persentase dari jumlah total unit yang akan menjadi sampel.
Momen ini sangat diperlukan dalam penelitian. Misalnya, jika Anda perlu memeriksa persentase produk-produk manisan berkualitas rendah di pabrik tertentu. Misalkan agregat umum sudah ditentukan. Diketahui bahwa per tahun perusahaan ini menghasilkan 1000 gula-gula. Jika Anda membuat sampel 100 produk gula acak dari seribu ini dan mengirimkannya ke pemeriksaan, kesalahan akan minimal. Secara kasar, sebuah penelitian disebut 10% dari semua produk, dan pada hasil yang kami dapat, dengan mempertimbangkan kesalahan keterwakilan, berbicara tentang kualitas semua produk yang buruk.
Dan jika Anda memiliki sampel 100 produk gula-gula dari agregat umum yang tidak terbatas, di mana mereka sebenarnya, mengakui, 1 juta unit, hasil sampel dan penelitian itu sendiri akan sangat penting dan tidak akurat. Apakah Anda merasakan perbedaannya? Oleh karena itu, kepastian populasi umum dalam banyak kasus sangat penting dan sangat mempengaruhi hasil penelitian.

Representatif Agregat
Jadi, sekarang salah satu masalah paling penting - apa yang harus menjadi sampel? Ini adalah momen utama dari penelitian ini. Pada tahap ini, perlu untuk menghitung sampel dan unit tertentu dari total di dalamnya. Set ini dipilih dengan benar jika fitur dan karakteristik tertentu dari populasi umum tetap selektif. Ini disebut perwakilan.
Dengan kata lain, jika, setelah pemilihan, bagian mempertahankan tren dan fitur yang sama dengan seluruh jumlah yang diselidiki, maka set seperti itu disebut perwakilan. Tetapi tidak setiap sampel spesifik dapat dipilih dari totalitas representatif. Ada objek penelitian seperti itu, sampel yang tidak bisa representatif. Dari sini dan konsep kesalahan keterwakilan terjadi. Tapi kita akan bicara tentang ini sedikit lagi.
Cara Membuat Sampel
Jadi, bahwa keterwakilannya maksimal, mengalokasikan tiga aturan sampel dasar:

Representasi Kesalahan (Kesalahan)
Karakteristik utama dari kualitas sampel yang dipilih adalah konsep "kesalahan representatif". Apa itu? Ini adalah perbedaan tertentu antara indikator pengamatan selektif dan padat. Dalam hal kesalahan, keterwakilan dibagi menjadi andal, biasa dan perkiraan. Dengan kata lain, deviasi yang diizinkan dalam jumlah hingga 3%, dari 3 hingga 10% dan dari 10 hingga 20%, masing-masing. Meskipun diinginkan dalam statistik bahwa kesalahan tidak melebihi 5-6%. Kalau tidak, ada alasan untuk berbicara tentang keterwakilan sampel yang tidak memadai. Untuk menghitung urgensi keterwakilan dan bagaimana pengaruhnya mempengaruhi populasi selektif atau umum, banyak faktor yang diperhitungkan:
- Probabilitas yang diperlukan untuk mendapatkan hasil yang akurat.
- Jumlah unit agregat selektif. Seperti yang disebutkan sebelumnya, semakin sedikit unit akan menjadi sampel, semakin besar akan ada kesalahan representatif, dan sebaliknya.
- Keseragaman totalitas yang diteliti. Semakin heterogenus adalah totalitas, semakin besar ketidakpastian keterwakilan. Kemungkinan agregat menjadi perwakilan tergantung pada keseragaman semua komponennya.
- Metode pemilihan unit di agregat selektif.
Dalam studi tertentu, persentase dari kesalahan rata-rata biasanya ditetapkan oleh peneliti sendiri berdasarkan program observasi dan sesuai dengan data studi yang dilakukan sebelumnya. Sebagai aturan, kesalahan pengambilan sampel yang valid dianggap sebagai kesalahan yang diizinkan (Representativeness) dalam 3-5%.

Lebih - tidak selalu lebih baik
Juga perlu diingat bahwa hal utama dalam organisasi pengamatan selektif adalah untuk membawa volumenya ke minimum yang diizinkan. Seharusnya tidak berusaha untuk mengurangi batas-batas kesalahan pengambilan sampel, karena hal ini dapat menyebabkan peningkatan ukuran sampel ini dan, oleh karena itu, meningkat dalam peningkatan pengeluaran pada pengamatan selektif.
Pada saat yang sama, tidak mungkin untuk secara berlebihan meningkatkan ukuran urgensi keterwakilan. Memang, dalam hal ini, meskipun akan ada penurunan jumlah agregat selektif, ini akan mengarah pada kemunduran akurasi hasil yang diperoleh.
Pertanyaan apa yang biasanya diletakkan di depan peneliti
Studi apa pun jika dilakukan, maka untuk beberapa tujuan dan untuk mendapatkan beberapa hasil. Ketika melakukan studi sampel, sebagai aturan, pertanyaan awal dimasukkan:

Metode untuk memilih unit penelitian dalam sampel
Tidak setiap sampel diwakili. Terkadang tanda yang sama berbeda secara umum secara umum dan di bagian-bagiannya. Untuk mencapai persyaratan representatif, disarankan untuk menggunakan berbagai teknik pengambilan sampel. Selain itu, penggunaan satu atau metode lain tergantung pada keadaan tertentu. Di antara teknik penciptaan sampel ini dibedakan:
- seleksi acak;
- pemilihan mekanis;
- seleksi tipikal;
- seleksi serial (sarang).
Pemilihan acak adalah sistem langkah-langkah yang ditujukan untuk pemilihan unit agregat acak, ketika probabilitas masuk ke sampel sama dengan semua unit populasi umum. Dianjurkan untuk menerapkan teknik ini hanya dalam kasus homogenitas dan sejumlah kecil tanda-tanda yang melekat di dalamnya. Jika tidak, beberapa fitur karakteristik risiko tidak tercermin dalam sampel. Tanda-tanda pemilihan acak didasarkan pada semua cara lain untuk membangun sampel.
Dengan pemilihan mekanis unit dilakukan melalui interval tertentu. Jika Anda perlu membentuk sampel kejahatan spesifik, Anda dapat menarik diri dari semua kartu akuntansi statistik dari kejahatan terdaftar setiap kartu 5, 10 atau 15, tergantung pada jumlah total dan ukuran sampel mereka. Kerugian dari metode ini adalah bahwa sebelum pemilihan perlu memiliki akuntansi penuh unit agregat, kemudian peringkat dan hanya setelah itu dimungkinkan untuk mencicipi dengan interval tertentu. Metode ini membutuhkan banyak waktu, jadi tidak sering digunakan.

Seleksi khas (zonasi) adalah jenis sampling, di mana populasi umum dibagi menjadi kelompok homogen pada tanda tertentu. Kadang-kadang peneliti menggunakan istilah lain alih-alih kelompok: "kabupaten" dan "zona". Kemudian, dari masing-masing kelompok secara acak, sejumlah unit dipilih secara proporsional dengan bobot spesifik kelompok dalam total agregat. Pilihan khas sering dilakukan dalam beberapa tahap.
Pilihan serial adalah metode di mana pemilihan unit dilakukan oleh kelompok (seri) dan semua unit grup (seri) yang dipilih tunduk pada survei. Keuntungan dari metode ini adalah bahwa kadang-kadang memilih unit individu lebih rumit daripada seri, misalnya, ketika mempelajari seseorang yang menjalani hukuman. Dalam kerangka area yang dipilih, zona menerapkan studi semua unit tanpa kecuali, misalnya, studi semua orang yang melayani hukuman di beberapa lembaga tertentu.
jenis sampling:
Sebenarnya acak;
Mekanis;
Khas;
Serial;
Digabungkan.
Sebenarnya sampel acak.ini adalah pemilihan unit dari agregat umum secara acak, tanpa elemen sistem. Namun, sebelum menghasilkan pemilihan diri sendiri, perlu memastikan bahwa semua unit populasi umum benar-benar memiliki peluang yang sama untuk masuk ke sampel, tidak ada bagian-bagian, mengabaikan unit individu, dan sejenisnya. Ini juga harus menetapkan batas-batas yang jelas dari populasi umum sehingga inklusi atau ketidakkatuan unit individu tidak menyebabkan keraguan. Misalnya, ketika memeriksa siswa, perlu untuk menunjukkan apakah orang-orang dalam cuti akademik akan diperhitungkan, mahasiswa universitas non-negara, sekolah militer, dll.; Ketika memeriksa perusahaan perdagangan, penting untuk menentukan apakah agregat umum akan mencakup paviliun perdagangan, tenda komersial dan benda-benda serupa lainnya. Pilihan diri sendiri dapat berulang dan restruktal. Untuk melaksanakan pemilihan penawaran dalam proses menggambar, banyak yang mengamuk kembali ke set asli tidak akan dikembalikan dan di masa depan pemilihan tidak terlibat. Saat menggunakan tabel angka acak, laju intraksi dicapai oleh bagian dalam hal mengulanginya di kolom atau kolom yang dipilih.
Sampel mekanik.ini diterapkan dalam kasus di mana populasi umum dengan cara apa pun diperintahkan, I.E. Ada urutan tertentu di lokasi unit (tabletom karyawan, daftar pemilih, nomor responden, rumah dan apartemen, dll.).
Kombinasi umum pemilihan mekanis dapat diperingkat atau disederhanakan oleh besarnya tanda atau berkorelasi dengannya, yang akan meningkatkan keterwakilan sampel. Namun, dalam hal ini, risiko kesalahan sistematis meningkat, terkait dengan meremehkan nilai atribut yang diteliti (jika nilai pertama dicatat dari setiap interval) atau dengan overestimasi (jika nilai yang terakhir direkam. dari setiap interval). Oleh karena itu, disarankan untuk mulai mulai dari tengah interval pertama
Pilihan tipikal.Metode pemilihan ini digunakan dalam kasus-kasus di mana semua unit populasi umum dapat dibagi menjadi beberapa kelompok khas. Selama pemeriksaan populasi, kelompok seperti itu mungkin, misalnya, area, sosial, usia atau kelompok pendidikan, Selama survei perusahaan - cabang atau sub-industri, bentuk kepemilikan, dll. Pilihan tipikal melibatkan sampel unit dari setiap kelompok khas dengan cara acak atau mekanis. Sejak perwakilan dari semua kelompok dalam satu atau lain proporsi, perwakilan dari semua kelompok, dengan satu atau lain cara, dicari, pengetikan populasi umum memungkinkan untuk menghilangkan efek dispersi antarkelompok pada kesalahan pengambilan sampel rata-rata, yang masuk Kasus ini hanya ditentukan oleh variasi intragroup.
Pemilihan unit ke sampel khas dapat diatur atau sebanding dengan volume kelompok-kelompok khas, atau sebanding dengan diferensiasi intragroup fitur.
Pilihan serial.Metode seleksi ini nyaman dalam kasus di mana unit totalitas digabungkan menjadi kelompok atau seri kecil. Sebagai seri, kemasan dengan sejumlah produk jadi, batch barang, kelompok siswa, brigade dan asosiasi lainnya dapat dipertimbangkan. Inti dari sampel serial terletak pada pemilihan acak atau mekanis dari seri, di mana survei unit yang padat dibuat.
Empiris dianggap sebagai salah satu cara utama mempelajari hubungan dan proses sosial. Mereka menyediakan informasi yang andal, lengkap, dan representatif.
Spesifisitas teknik.
Empiris memberikan penerimaan pengetahuan faktual. Mereka berkontribusi pada pembentukan dan generalisasi keadaan dengan mengorbankan pendaftaran peristiwa yang dimediasi atau langsung yang melekat dalam hubungan yang dipelajari, objek, fenomena. Teknik empiris berbeda dari fakta teoritis bahwa subjek analisis adalah:
- Perilaku individu dan kelompok mereka.
- Aktifitas manusia.
- Tindakan verbal individu, penilaian mereka, pandangan, pendapat.
Studi sampel.
Pembelajaran empiris selalu difokuskan pada mendapatkan informasi objektif dan akurat, data kuantitatif. Dalam hal ini, ketika dipenuhi, perlu untuk memastikan keterwakilan informasi. Dengan demikian, nilai yang benar sudah benar agregat selektif. saya t Ini berarti bahwa pemilihan harus dilakukan sehingga data yang diperoleh dari kelompok sempit mencerminkan tren yang terjadi pada total massa responden. Misalnya, ketika mensurvei 200-300 orang, data yang diperoleh dapat diekstrapolasi ke semua populasi perkotaan. Indikator agregat selektif memungkinkan pendekatan yang berbeda dengan studi proses sosial ekonomi di wilayah tersebut secara keseluruhan.

Terminologi
Untuk pemahaman yang lebih baik tentang masalah yang terkait dengan penelitian selektif, perlu untuk mengklarifikasi beberapa definisi. Unit observasi adalah sumber informasi langsung. Mereka mungkin merupakan individu, kelompok, dokumen, organisasi, dan sebagainya yang terpisah. Agregat umum adalah Kompleks unit observasi. Mereka semua harus terkait dengan masalah yang dipelajari. Analisis langsung tunduk pada. Studi ini dilakukan sesuai dengan metode yang dikembangkan untuk mengumpulkan informasi. Untuk menentukan bagian ini dari seluruh array penggunaan responden konsep "agregat selektif". Properti ini mencerminkan parameter utama dari total massa orang yang disebut keterwakilan. Dalam beberapa kasus tidak ada kebetulan. Kemudian mereka berbicara tentang kesalahan riwaknya.
Memberikan Representativitas
Rincian masalah yang terkait dengannya dibahas dalam kerangka statistik. Masalah dibedakan dengan kompleksitas, karena, di satu sisi, diusulkan untuk memberikan representasi kuantitatif yang memberi populasi umum. saya t Menunjukkan, khususnya, bahwa kelompok responden harus disajikan dalam angka optimal. Kuantitas harus cukup untuk representasi normal. Di sisi lain, ada juga representasi kualitatif. Ini melibatkan subjek tertentu, yang terbentuk agregat selektif. saya t Ini berarti bahwa, misalnya, keterwakilan tidak dapat didiskusikan, jika hanya laki-laki yang diwawancarai atau hanya perempuan, orang lanjut usia baik pemuda. Studi harus dilakukan di semua kelompok yang diwakili.

Sampel karakteristik.
Istilah ini dipertimbangkan dalam dua aspek. Pertama-tama, ini didefinisikan sebagai kompleks elemen dari beragam orang yang berpelajaran - ini sedang dipelajari - ini agregat selektif. saya t Juga, proses menciptakan kategori responden tertentu dengan ketentuan keterwakilan yang diperlukan. Dalam praktiknya, beberapa jenis dan jenis pemilihan menonjol. Pertimbangkan mereka.
Jenis
Ada tiga dari mereka:
- Spontan agregat selektif. saya t Satu set responden dipilih pada prinsip sukarela. Pada saat yang sama, ketersediaan unit dari total massa orang menjadi kelompok studi tertentu dipastikan. Seleksi spontan dalam praktik cukup sering digunakan. Misalnya, dengan jajak pendapat di pers, melalui pos. Namun, teknik ini memiliki kelemahan yang signifikan. Tidak mungkin untuk menghadirkan seluruh jumlah sampel umum secara kualitatif. Teknik ini diterapkan berdasarkan ekonomi. Dalam beberapa jajak pendapat, opsi ini adalah satu-satunya yang mungkin.
- Spontan agregat selektif. saya t Salah satu teknik utama yang digunakan dalam penelitian ini. Sebagai prinsip utama seleksi tersebut, adalah mungkin untuk memastikan peluang untuk setiap unit pengamatan untuk mendapatkan dari total massa individu ke dalam kelompok sempit. Ini menggunakan teknik yang berbeda. Misalnya, itu bisa menjadi lotere, pemilihan mekanis, tabel angka acak.
- Sampel bertingkat (tambang). Ini didasarkan pada pembentukan model kualitatif dari total massa responden. Setelah itu, pemilihan unit dilakukan dalam totalitas selektif. Misalnya, ini dilakukan berdasarkan usia atau jenis kelamin, menurut populasi dan sebagainya.
Tampilan
Sampel berikut ada:

Selain itu
Sampel juga dapat bergantung dan mandiri. Dalam kasus pertama, prosedur eksperimental dan hasil yang akan diperoleh untuk satu kelompok responden selama itu memiliki dampak tertentu pada yang lain. Dengan demikian, sampel independen tidak berniat memiliki dampak seperti itu. Namun di sini, Anda harus memperhatikan satu poin penting. Satu kelompok subjek sehubungan dengan mana pemeriksaan psikologis dilakukan dua kali (bahkan jika itu bertujuan mempelajari berbagai kualitas, fitur, fitur), default akan dianggap tergantung.
Pilihan probabilistik
Pertimbangkan beberapa jenis sampel:
- Acak. Ini melibatkan homogenitas total agregat, satu kemungkinan ketersediaan semua komponen, serta keberadaan daftar lengkap elemen. Sebagai aturan, tabel dengan angka acak digunakan selama pemilihan.
- Mekanis. Jenis sampling acak ini menyiratkan pemesanan pada fitur tertentu. Misalnya dengan nomor telepon, dalam urutan abjad, berdasarkan tanggal lahir dan seterusnya. Komponen pertama dipilih secara acak. Selanjutnya, pemilihan setiap elemen K dengan langkah n. Besarnya agregat total akan menjadi n \u003d k * n.
- Stratic. Sampel ini digunakan dalam inhomogenitas total agregat. Yang terakhir dibagi menjadi strata (kelompok). Di masing-masing dari mereka, pemilihan dilakukan dengan cara mekanis atau acak.
- Serial. Pemilihan kelompok tidak sengaja. Di dalamnya, benda-benda dipelajari oleh padatan.
Pilihan yang luar biasa
Mereka menyarankan sampel tidak pada prinsip kebetulan, tetapi menurut tanda subyektif: khas, aksesibilitas, representasi yang sama dan sebagainya. Kategori ini mencakup pilihan:

Nuansa
Untuk memberikan keterwakilan, daftar unit agregat yang akurat dan lengkap. Objek pengamatan, sebagai aturan, adalah satu orang. Pilihan dari daftar lebih baik untuk dilakukan, penomoran unit dan menerapkan tabel dengan angka acak. Tetapi metode quasonicound sering digunakan cukup sering. Ini menyiratkan pemilihan dari daftar masing-masing el elemen.
Faktor yang mempengaruhi
Volume agregat disebut jumlah unitnya. Menurut para ahli, itu tidak harus besar. Niscaya, lebih banyak nomor Responden, semakin akurat hasilnya. Namun, bersama dengan ini, sejumlah besar tidak selalu menjamin kesuksesan. Misalnya, ini terjadi ketika array keseluruhan responden tidak seragam. Homogen akan dianggap kombinasi seperti itu, di mana parameter yang dikendalikan, misalnya, tingkat literasi didistribusikan secara merata, yaitu, tidak ada kekosongan atau penebalan. Dalam hal ini, itu akan cukup untuk mewawancarai beberapa orang. Menurut hasil survei, akan mungkin untuk menyimpulkan bahwa kebanyakan orang memiliki tingkat literasi yang normal. Ini mengikuti dari ini bahwa dampak informasi bukan tanda kuantitatif, tetapi karakteristik kualitatif agregat adalah tingkat homogenitasnya, pada khususnya.

Kesalahan
Mereka mewakili penyimpangan parameter rata-rata sampel yang ditetapkan pada nilai-nilai total massa responden. Dalam praktiknya, kesalahan ditentukan oleh perbandingan. Selama pemeriksaan orang dewasa, korespondensi, akuntansi statistik, serta hasil survei sebelumnya biasanya berlaku. Parameter kontrol biasanya melakukan perbandingan set rata-rata agregat (umum dan selektif), definisi sesuai dengan kesalahan ini dan penurunan defleksi ini disebut sebagai representatif.
kesimpulan.
Sebuah studi selektif adalah metode untuk mengumpulkan data tentang instalasi dan perilaku orang melalui survei kelompok responden yang dipilih secara khusus. Penerimaan ini dianggap dapat diandalkan dan ekonomis, meskipun memerlukan beberapa teknik. Basis adalah set selektif. Ini bertindak sebagai proporsi tertentu dari total massa orang. Pilihan dibuat menggunakan teknik khusus dan ditujukan untuk mendapatkan informasi tentang seluruh totalitas. Yang terakhir, pada gilirannya, diwakili oleh semua objek publik yang mungkin atau kelompok yang akan dipelajari. Seringkali, agregat umum sangat besar sehingga survei dari setiap perwakilan akan cukup mahal dan proses yang memberatkan. Oleh karena itu, modelnya yang dikurangi digunakan. Dalam satu set selektif, semua yang menerima kuesioner dimasukkan, yang disebut sebagai responden yang benar-benar bertindak sebagai objek penelitian. Sederhananya, itu merupakan banyak orang yang disurvei.

Kesimpulan
Tujuan survei ditentukan oleh kategori tertentu yang termasuk dalam populasi umum. Sedangkan untuk bagian tertentu dari total massa orang, tunduk pada subjek yang termasuk dalam kelompok dengan bantuan perhitungan matematika. Untuk pemilihan unit, deskripsi objek dari set asli diperlukan. Setelah menentukan jumlah subjek, penerimaan atau metode pembentukan grup ditentukan. Hasil survei akan memungkinkan untuk menggambarkan tanda yang diteliti mengenai semua perwakilan dari total massa masyarakat. Ketika praktik menunjukkan, studi selektif, dan bukan solid dilakukan.
Prosedur untuk menyusun rencana sampel termasuk Solusi berurutan dari tiga tugas berikut:
Penentuan objek penelitian;
Penentuan struktur pengambilan sampel;
Penentuan sampel.
Biasanya, obyek Pemasaran Riset Ini adalah kombinasi objek observasi, yang konsumen, karyawan perusahaan, perantara, dll. Dapat dimainkan. Jika totalitas ini sangat kecil sehingga tim peneliti memiliki kemampuan kerja, keuangan dan sementara yang diperlukan untuk menetapkan kontak dengan masing-masing elemennya, cukup realistis untuk melakukan studi berkelanjutan dari seluruh populasi. Dalam hal ini, dengan mendefinisikan objek penelitian, Anda dapat melanjutkan ke prosedur berikut (pilihan metode pengumpulan data, instrumen penelitian dan metode komunikasi dengan audiens).
Namun, dalam praktiknya sangat sering tidak mungkin atau sesuai untuk melakukan studi berkelanjutan dari seluruh populasi. Untuk melakukan ini, mungkin ada alasan berikut:
Ketidakmampuan untuk menetapkan kontak dengan beberapa elemen totalitas;
Biaya besar yang tidak masuk akal untuk melakukan studi yang solid atau ketersediaan pembatasan keuangan yang tidak memungkinkan penelitian yang solid;
Batas waktu yang disarankan dialokasikan untuk penelitian karena kerugian dengan relevansi informasi atau alasan lain dan tidak mengizinkan pengumpulan, sistematisasi dan analisis data yang luas untuk seluruh totalitas.
Oleh karena itu, agregat besar dan tersebar sering dipelajari dengan pengambilan sampel, di mana, seperti yang diketahui, bagian dari agregat dipahami untuk mempersoneksi totalitas secara keseluruhan.
Keakuratan yang dengannya sampel mencerminkan totalitas secara keseluruhan tergantung pada struktur dan ukuran pengambilan sampel.
Bedakan dua pendekatan dengan struktur pengambilan sampel - Probabilistik dan deterministik.
Pendekatan probabilistik untuk struktur pengambilan sampel Ini mengasumsikan bahwa elemen agregat dapat dipilih dengan probabilitas tertentu (bukan nol). Ada jenis yang berbeda Sampel berdasarkan teori probabilitas (khas, bersarang, dll.). Praktek yang paling mudah dan umum adalah sampel acak sederhana, di mana setiap elemen agregat memiliki pilihan yang sama untuk penelitian ini.
Sampel probabilistik lebih akurat, memungkinkan peneliti untuk memperkirakan tingkat keandalan data yang dikumpulkan olehnya, meskipun lebih sulit dan lebih mahal daripada deterministik.
Pendekatan deterministik. ke struktur sampel Ini mengasumsikan bahwa pilihan elemen-elemen yang ditetapkan dibuat oleh metode berdasarkan pada pertimbangan kenyamanan, atau pada solusi peneliti atau pada kelompok kontinjensi.
untuk kenyamanan pertimbanganIni terdiri dalam memilih elemen agregat berdasarkan kesederhanaan menghubungi kontak dengan mereka. Ketidaksempurnaan dari metode ini disebabkan oleh riuh rendah dari sampel yang diperoleh, karena Elemen agregat yang nyaman untuk peneliti mungkin tidak cukup karakteristik perwakilan dari agregat karena pemilihan non-acak dan tidak masuk akal.
Namun, di sisi lain, kesederhanaan, efisiensi dan efisiensi penelitian yang dilakukan oleh metode ini telah memperoleh cukup luas dalam praktik dan, di atas semua, ketika melakukan studi pendahuluan yang bertujuan mengklarifikasi masalah besar.
Metode Pembentukan Sampling Berbasis pada keputusan penelitiIni terdiri dalam memilih unsur-unsur agregat, yang, menurut pendapatnya, adalah perwakilan karakteristiknya. Metode ini lebih sempurna dari yang sebelumnya, karena didasarkan pada orientasi pada perwakilan karakteristik dari kecurangan yang diteliti, meskipun dipilih berdasarkan representasi subyektif para peneliti tentang hal itu.
Metode pengambilan sampel berdasarkan standar kontingenIni terdiri dalam memilih elemen-elemen karakteristik agregat sesuai dengan karakteristik agregat yang diperoleh sebelumnya. Karakteristik ini dapat diperoleh dengan melakukan studi pendahuluan dan, berbeda dengan metode sebelumnya, tidak menanggung sifat subyektif. Oleh karena itu, metode ini lebih sempurna, memungkinkan Anda untuk mendapatkan set selektif yang tidak kurang representatif daripada sampel probabilistik dengan biaya pengawasan yang jauh lebih sedikit.
Memilih struktur sampel (pendekatan untuk pembentukannya, jenis pembentukan probabilistik atau rolling dari sampel deterministik), peneliti harus menentukan volume, I.E. Jumlah elemen agregat selektif.
Volume pengambilan sampel. Menentukan keakuratan informasidiperoleh sebagai hasil penelitiannya, serta biaya yang diperlukan untuk melakukan penelitian. Ukuran sampel tergantung Dari tingkat homogenitas atau varietas benda yang diteliti.
Semakin besar ukuran sampel, semakin tinggi keakuratannya dan lebih banyak biaya untuk survei. Dengan pendekatan probabilistik untuk struktur pengambilan sampel, volumenya dapat ditentukan dengan menggunakan formula statistik yang terkenal, berdasarkan persyaratan yang ditentukan untuk keakuratannya.
Dalam praktiknya, beberapa pendekatan digunakan untuk mendefinisikan sampling:
1. Pendekatan sewenang-wenang Berdasarkan penggunaan "aturan jempol". Misalnya, tidak perlu bahwa sampel harus 5% dari totalitas untuk mendapatkan hasil yang akurat. Pendekatan ini sederhana dan mudah dilakukan, tetapi tidak mungkin untuk menetapkan keakuratan hasil yang diperoleh. Dengan totalitas yang cukup besar, itu juga bisa sangat mahal.
Ukuran sampel dapat ditetapkan berdasarkan beberapa kondisi yang telah ditentukan. Misalnya, pelanggan riset pemasaran tahu bahwa ketika mempelajari opini publik, sampel biasanya 1000-1200 orang, jadi dia merekomendasikan peneliti untuk mematuhi angka ini. Dalam hal studi tahunan diadakan di pasar, maka pada setiap tahun ia menggunakan sampel dengan volume yang sama. Berbeda dengan pendekatan pertama, logika terkenal digunakan di sini dalam menentukan volume sampel, yang, bagaimanapun, sangat rentan.
Misalnya, ketika melakukan penelitian tertentu, akurasi mungkin diperlukan kurang dari ketika mempelajari opini publik, dan total totalitas mungkin berkali-kali kurang daripada ketika mempelajari opini publik. Dengan demikian, pendekatan ini tidak memperhitungkan keadaan saat ini dan mungkin cukup mahal.
Dalam beberapa kasus, sebagai argumen utama, ketika menentukan volume sampel, biaya survei digunakan. Dengan demikian, anggaran penelitian pemasaran menyediakan survei tertentu yang tidak dapat dilampaui. Jelas, nilai informasi yang diterima tidak diperhitungkan. Namun, dalam beberapa kasus, sampel kecil dapat memberikan hasil yang cukup akurat.
Tampaknya masuk akal untuk memperhitungkan biaya tidak secara absolut, tetapi sehubungan dengan kegunaan informasi yang diperoleh sebagai hasil dari survei yang dilakukan. Pelanggan dan peneliti harus mempertimbangkan berbagai volume sampel dan metode pengumpulan data, biaya, memperhitungkan faktor-faktor lain
2. Ukuran sampel pada tingkat interval rahasia dari kesalahan yang valid, Apa, seperti yang telah disebutkan, diberikan dengan akurasi generalisasi akhir: dari meningkat menjadi perkiraan. Namun, ada dalam pikiran yang disebut kesalahan acak yang terkait dengan sifat kesalahan statistik. Mereka dihitung sebagai kesalahan representatif sampel probabilistik.
V.i. Paniotto mengutip perhitungan sampel representatif berikut dengan izin kesalahan 5 persen (Tabel 4.2).
Tabel 4.2.
Tabel sampel yang dihitung
Untuk kombinasi lebih dari 100.000 sampel adalah 400 unit. Jika saya ingat bahwa set angka umum dari 5 ribu dan lebih, kemudian, menurut perhitungan penulis yang sama, Anda dapat menentukan nilai kesalahan aktual sampel, tergantung pada volumenya, yang sangat Penting bagi kami, mengingat bahwa nilai kesalahan yang valid tergantung pada tujuan penelitian dan opsional harus mendekati tingkat 5 persen.
Tabel 4.3.
Tabel yang dihitung
|
Pengambilan sampel, jika agregat umum 5000 | ||||||||
|
Kesalahan sebenarnya dalam volume sampel ini,% |
Seiring dengan kesalahan sistematis acak mungkin. Mereka bergantung pada organisasi pemeriksaan selektif. Ini adalah berbagai pengambilan sampel mengimbangi salah satu kutub parameter selektif.
3. Pengambilan sampel berdasarkan analisis statistik . Pendekatan ini didasarkan pada penentuan sampling minimum berdasarkan persyaratan tertentu untuk keandalan dan keandalan hasil yang diperoleh. Ini juga digunakan dalam analisis hasil yang diperoleh untuk subkelompok individu yang dibentuk sebagai bagian dari pemilihan di lantai, usia, tingkat pendidikan, dll. Persyaratan untuk keandalan dan keakuratan hasil untuk subkelompok individu mendikte persyaratan tertentu untuk ukuran sampel secara keseluruhan.
Pendekatan yang palingan secara teoritis dan benar untuk menentukan volume sampel didasarkan pada perhitungan interval yang andal. Konsep variasi mencirikan besarnya tanggapan yang salah (serupa) responden terhadap pertanyaan tertentu. Dalam rencana yang lebih ketat, variasi nilai-nilai tanda apa pun dalam suatu set disebut perbedaan nilainya dari unit yang berbeda diatur dalam periode atau waktu yang sama. Tanggapan untuk pertanyaan survei biasanya diwakili dalam bentuk kurva distribusi (Gbr. 4.1). Dengan kesamaan yang tinggi, jawabannya berbicara tentang variasi rendah (kurva distribusi sempit) dan dengan kesamaan kesamaan rendah - tentang variasi tinggi (kurva distribusi yang luas).
Sebagai ukuran variasi, deviasi kuadratik rata-rata biasanya diambil, yang mencirikan jarak rata-rata dari evaluasi rata-rata tanggapan masing-masing responden dengan pertanyaan tertentu.
Variasi kecil.
Variasi tinggi
Ara. 4.1. Kurva Variasi dan Distribusi
Karena semua solusi pemasaran diterima dalam ketidakpastian, keadaan ini disarankan untuk diperhitungkan saat menentukan ukuran sampel. Karena definisi nilai yang diteliti untuk satu set dalam sempit dilakukan berdasarkan statistik selektif, rentang (interval kepercayaan) harus diatur, yang diharapkan diperkirakan totalitas, dan kesalahan definisi mereka.
Interval kepercayaan adalah kisaran, titik ekstrem yang sesuai dengan persentase tertentu dari jawaban tertentu untuk beberapa pertanyaan. Interval kepercayaan terkait erat dengan deviasi kuadratik rata-rata dari atribut yang diteliti dalam populasi umum: semakin banyak interval kepercayaan yang lebih luas untuk memasukkan persentase jawaban tertentu.
Interval kepercayaan, sama dengan atau 95%, atau 99%, standar ketika melakukan riset pemasaran. Tidak ada perusahaan yang melakukan riset pemasaran dengan membentuk beberapa sampel. Dan statistik matematika memungkinkan untuk mendapatkan beberapa informasi tentang distribusi selektif, hanya memiliki data pada variasi satu sampel.
Indikator evaluasi evaluasi, yang sebenarnya untuk ditetapkan secara keseluruhan, dari penilaian yang diharapkan menjadi sampel khas, adalah kesalahan kuadrat sedang. Selain itu, semakin sedikit sampling, semakin kecil kesalahannya. Nilai variasi yang tinggi menentukan nilai tinggi kesalahan dan sebaliknya.
Ketika hanya ada dua opsi untuk pertanyaan yang ditugaskan, dinyatakan sebagai persentase (ukuran persentase digunakan), ukuran sampel ditentukan oleh rumus berikut:

di mana n adalah ukuran sampel; Z adalah penyimpangan yang dinormalisasi, ditentukan berdasarkan tingkat kepercayaan yang dipilih; Variasi P - Ditemukan untuk pengambilan sampel; G - (100-P); E - Kesalahan yang Diizinkan.
Dalam menentukan indikator variasi untuk set tertentu, pertama-tama, disarankan untuk melakukan analisis kualitatif awal dari pembakaran yang diteliti, pertama-tama menetapkan kesamaan unit agregat dalam hubungan demografis, sosial dan lainnya minat kepada peneliti. Dimungkinkan untuk melakukan studi percontohan, penggunaan hasil studi tersebut dilakukan di masa lalu. Ketika menggunakan persentase ukuran variabilitas diperhitungkan bahwa variabilitas maksimum dicapai untuk P \u003d 50%, yang merupakan kasus terburuk. Selain itu, indikator ini secara radikal tidak mempengaruhi ukuran sampel. Pendapat penelitian pelanggan tentang volume sampling juga diperhitungkan.
Dimungkinkan untuk menentukan ukuran sampel berdasarkan penggunaan nilai rata-rata, dan bukan nilai persentase.

di mana S adalah penyimpangan kuadrat sekunder.
Dalam praktiknya, jika sampel dibentuk baru dan survei serupa tidak dilakukan, maka S tidak diketahui. Dalam hal ini, disarankan untuk menetapkan kesalahan E dalam fraksi standar deviasi. Formula yang dihitung dikonversi dan mengakuisisi formulir berikut:
 dimana
dimana  .
.
Di atas ada percakapan tentang agregat ukuran yang sangat besar. Namun, dalam beberapa kasus, agregat tidak besar. Biasanya, jika sampel kurang dari lima persen dari agregat, agregat dianggap besar dan perhitungan dilakukan sesuai dengan aturan di atas. Jika ukuran sampel melebihi 5% dari agregat, yang terakhir dianggap kecil dan rumus di atas diperkenalkan oleh koefisien koreksi.
Ukuran sampel dalam hal ini didefinisikan sebagai berikut:
 ,
,
di mana n adalah ukuran sampel untuk agregat kecil; N 0 - ukuran sampel dihitung sesuai dengan formula di atas; N adalah volume populasi umum.
Jelas, penggunaan sampel yang lebih kecil akan menyebabkan penghematan waktu dan uang.
Rumus di atas untuk menghitung ukuran sampel didasarkan pada asumsi bahwa semua aturan formasi sampel diamati dan satu-satunya kesalahan sampel adalah kesalahan karena volumenya. Namun, harus diingat bahwa ukuran sampel menentukan keakuratan hasil yang diperoleh, tetapi bukan keterwakilan mereka.
Yang terakhir ditentukan oleh metode pengambilan sampel. Semua formula untuk menghitung ukuran sampel menunjukkan bahwa representatif dijamin dengan menggunakan prosedur pengambilan sampel probabilistik yang benar.
Volume, sampel ditentukan oleh analitis, tujuan penelitian, dan keterwakilannya adalah target pemasangan program. Ini adalah program yang menetapkan citra populasi umum yang diperlukan untuk pengambilan sampel. Apakah itu akan menjadi populasi atau formasi struktural khusus, semua elemen objek sedang dipelajari atau hanya dialokasikan sesuai dengan program kriteria yang ditentukan, populasi umum adalah semua unit yang ditentukan dalam program objek.
Selama pendekatan deterministik terhadap struktur sampel, secara umum, tidak mungkin untuk secara akurat menentukan volumenya sesuai dengan kriteria yang ditentukan untuk keandalan informasi yang diterima. Dalam hal ini, ukuran sampel dapat ditentukan secara empiris. Aktivitas penelitian pemasaran di luar negeri dapat berfungsi sebagai pedoman. Jadi, ketika memeriksa pembeli, akurasi tinggi sampel dipastikan, bahkan jika volumenya tidak melebihi 1% dari seluruh set ketika melakukan jajak pendapat untuk pelanggan perusahaan ritel menengah dan besar, jumlah responden (volume pengambilan sampel) biasanya berfluktuasi dari 500 hingga 1000 orang.
Nilai prosedur untuk memilih metode pengumpulan informasi utama, dan instrumen penelitian ini adalah bahwa hasil pemilihan ini didefinisikan baik keandalan dan keakuratan informasi yang akan diperoleh dan durasinya, dan tingginya biaya. koleksi.
Untuk menentukan probabilitas peristiwa yang Anda minati, kami menggunakan metode selektif: kami lakukan n. Eksperimen independen, di masing-masing dapat terjadi (atau tidak terjadi) peristiwa A (probabilitas r. Penampilan peristiwa A dalam setiap percobaan konstan). Kemudian frekuensi relatif P * penampilan peristiwa TAPI Dalam seri n. Tes diterima sebagai perkiraan titik untuk kemungkinan. p. Penampilan Acara TAPI Dalam tes terpisah. Dalam hal ini, nilai P * disebut bagikan selektif Penampilan acara TAPI, dan r - umum .
Berdasarkan penyelidikan dari teorema batas pusat (Teorema Moorev-Laplace), frekuensi relatif dari peristiwa dengan sejumlah besar pengambilan sampel dapat dipertimbangkan secara normal didistribusikan dengan parameter M (P *) \u003d P dan
Oleh karena itu, dengan N\u003e 30, interval kepercayaan untuk pangsa umum dapat dibangun menggunakan formula:

di mana Anda berada di atas meja fungsi Laplace, dengan mempertimbangkan probabilitas kepercayaan yang diberikan γ: 2F (U CR) \u003d γ.
Dengan ukuran sampel kecil N≤30, kesalahan ε ditentukan oleh tabel distribusi siswa: ![]() di mana t kr \u003d t (k; α) dan jumlah derajat kebebasan k \u003d n-1 probabilitas α \u003d 1-γ (wilayah dua sisi).
di mana t kr \u003d t (k; α) dan jumlah derajat kebebasan k \u003d n-1 probabilitas α \u003d 1-γ (wilayah dua sisi).
Formula valid jika pemilihan dilakukan secara acak lagi (set umum tak terbatas), jika tidak, perlu untuk membuat koreksi terhadap kekhasan pemilihan (tabel).
Kesalahan pengambilan sampel rata-rata untuk pangsa umum
| General agregate. | Tak terbatas | Volume terbatas N. |
| Seleksi tipe. | Ulang | Menangkap |
| Kesalahan sampel rata-rata |
Rumus untuk menghitung ukuran sampel dengan metode seleksi yang terjangkau
| Metode seleksi | Pengambilan sampel formula numerik. | ||
| untuk menengah | untuk berbagi | ||
| Ulang | |||
| Menangkap | |||
Tugas Umum
Pertanyaannya "mencakup interval kepercayaan dari nilai yang ditentukan p 0?" - Anda dapat menjawab dengan memeriksa hipotesis statistik H 0: P \u003d P 0. Diasumsikan bahwa eksperimen dilakukan sesuai dengan skema uji Bernoulli (independen, probabilitas p. Penampilan Acara TAPI konstan). Dengan volume sampel n. Tentukan frekuensi relatif P * penampilan acara A: Di mana m. - Jumlah peristiwa TAPI Dalam seri n. Tes. Untuk memeriksa hipotesis H 0, statistik digunakan, memiliki distribusi normal standar dengan sampel yang cukup besar (Tabel 1).Tabel 1 - hipotesis tentang proporsi umum
Hipotesa | H 0: P \u003d P 0 | H 0: P 1 \u003d P 2 |
| Asumsi | Skema tes Bernoulli | Skema tes Bernoulli |
| Peringkat sampel |  |
|
| Statistik K. |  |  |
| Distribusi statistik K. | Standar Normal N (0,1) |
Contoh nomor 1. Dengan bantuan pemilihan ulang acak, manajemen perusahaan melakukan survei sampel 900 karyawannya. Di antara para responden ternyata 270 wanita. Bangun interval kepercayaan, dengan probabilitas 0,95 yang meliputi proporsi sejati perempuan di seluruh tim perusahaan.
Keputusan. Dengan syarat, pangsa sampel wanita adalah (frekuensi relatif perempuan di antara semua responden). Karena seleksi diulangi, dan ukuran sampelnya besar (n \u003d 900) kesalahan pemilihan ditentukan oleh rumus ![]()
Nilai U KR menemukan tabel fungsi Laplace dari rasio 2F (U CR) \u003d γ, I.E. ![]() Fungsi Laplace (Lampiran 1) mengambil nilai 0,475 di U KR \u003d 1,96. Oleh karena itu, kesalahan batas
Fungsi Laplace (Lampiran 1) mengambil nilai 0,475 di U KR \u003d 1,96. Oleh karena itu, kesalahan batas ![]() dan interval kepercayaan yang diinginkan
dan interval kepercayaan yang diinginkan
(P - ε, p + ε) \u003d (0,3 - 0,18; 0,3 + 0,18) \u003d (0,12; 0,48)
Jadi, dengan probabilitas 0,95, dapat dijamin bahwa proporsi perempuan di seluruh tim perusahaan berada di kisaran 0,12 hingga 0,48.
Contoh nomor 2. Pemilik tempat parkir membaca hari "sukses" jika tempat parkir diisi dengan lebih dari 80%. Selama tahun ini, 40 pemeriksaan parkir dilakukan, di mana 24 "sukses". Dengan probabilitas 0,98, temukan interval kepercayaan untuk mengevaluasi bagian sebenarnya dari hari-hari "sukses" selama tahun tersebut.
Keputusan. Saham sampel hari "sukses" adalah
Pada fungsi tabel Laplace, kita akan menemukan nilai u cr dengan yang diberikan
probabilitas kepercayaan
F (2.23) \u003d 0,49, U kr \u003d 2.33.
Mempertimbangkan pemilihan tidak memungkinkan (mis., Dua cek tidak dilakukan dalam satu hari), kami menemukan kesalahan batas: ![]()
di mana n \u003d 40, n \u003d 365 (hari). Dari sini ![]()
dan interval kepercayaan untuk saham umum: (p - ε, p + ε) \u003d (0,6 - 0,17; 0,6 + 0,17) \u003d (0,43; 0,77)
Dengan probabilitas 0,98, dapat diharapkan bahwa bagian dari hari-hari "sukses" selama tahun ini berada dalam kisaran dari 0,43 hingga 0,77.
Contoh nomor 3. Memeriksa 2500 produk di pesta, menemukan bahwa 400 produk dari kelas tertinggi, dan N-M - No. Berapa banyak yang Anda butuhkan untuk memeriksa produk untuk menentukan bagian dari nilai tertinggi dengan keyakinan 95% hingga 0,01?
Solusi Kami sedang mencari rumus untuk menentukan jumlah pengambilan sampel untuk pemilihan ulang.
F (t) \u003d γ / 2 \u003d 0,95 / 2 \u003d 0,475 dan nilai ini pada tabel Laplace sesuai dengan t \u003d 1,96
Berbagi selektif w \u003d 0,16; Kesalahan sampling ε \u003d 0,01
Contoh nomor 4. Batch produk diterima jika kemungkinan produk akan menjadi standar yang sesuai setidaknya 0,97. Di antara 200 produk yang dipilih secara acak dari batch yang diterima adalah standar yang relevan 193. Apakah mungkin pada tingkat signifikansi α \u003d 0,02 untuk menerima partai?
Keputusan. Kami merumuskan hipotesis utama dan alternatif.
H 0: P \u003d P 0 \u003d 0,97 - Bagikan Umum Tidak Diketahui p. sama dengan nilai yang diberikan p 0 \u003d 0,97. Sehubungan dengan kondisi - kemungkinan bahwa bagian dari batch yang diterima akan relevan dengan standar, setara dengan 0,97; itu. Batch produk dapat diambil.
H 1: P<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Nilai statistik yang diamati K. (Tabel) menghitung pada nilai-nilai yang ditentukan p 0 \u003d 0,97, n \u003d 200, m \u003d 193
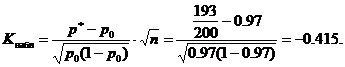
Signifikansi kritis menemukan tabel fungsi Laplace dari kesetaraan
![]()
Di bawah kondisi α \u003d 0,02, dari sini F (KKR) \u003d 0,48 dan KKR \u003d 2.05. Wilayah kritis sisi kiri, I.E. Ini adalah interval (-∞; -k kp) \u003d (-∞; -2.05). Nilai yang diamati untuk pusar \u003d -0.415 bukan milik area kritis, oleh karena itu, pada tingkat signifikansi ini tidak ada alasan untuk membelokkan hipotesis utama. Anda dapat mengambil batch produk.
Contoh nomor 5. Dua tanaman membuat jenis detail yang sama. Untuk menilai kualitasnya, sampel dibuat dari produk-produk dari tanaman ini dan hasil berikut diperoleh. Di antara 200 produk terpilih dari pabrik pertama ternyata 20 cacat, di antara 300 produk dari pabrik kedua - 15 cacat.
Pada tingkat kepentingan 0,025, cari tahu apakah ada perbedaan yang signifikan karena bagian-bagian yang diproduksi oleh tanaman ini.
Di bawah kondisi α \u003d 0,025, maka f (CKR) \u003d 0,4875 dan KKR \u003d 2.24. Dengan alternatif bilateral, area nilai yang diizinkan memiliki bentuk (-2.24; 2.24). Nilai yang diamati K Navel \u003d 2,15 jatuh ke dalam interval ini, I.E. Pada tingkat signifikansi ini tidak ada alasan untuk menolak hipotesis utama. Tanaman membuat produk dengan kualitas yang sama.