ეს ხშირად ხდება, რომ აუცილებელია ნებისმიერი სოციალური ფენომენის ანალიზი და ამის შესახებ ინფორმაციის მიღება. ასეთი ამოცანები ხშირად ხდება სტატისტიკებში სტატისტიკური კვლევები. შეამოწმეთ სრულად გარკვეული სოციალური ფენომენი ყველაზე ხშირად შეუძლებელია. მაგალითად, როგორ უნდა გაირკვეს მოსახლეობის აზრი ან კონკრეტული ქალაქის მცხოვრებთა ყველა კითხვა? ჰკითხეთ აბსოლუტურად ყველა - საქმე თითქმის შეუძლებელია და ძალიან შრომატევადი. ასეთ შემთხვევებში ჩვენ გვჭირდება ნიმუში. ეს არის ზუსტად კონცეფცია, რომელზეც თითქმის ყველა კვლევა და ტესტები ეფუძნება.
რა არის ნიმუში
კონკრეტული სოციალური ფენომენის ანალიზისას, აუცილებელია ამის შესახებ ინფორმაციის მიღება. თუ თქვენ მიიღებთ რაიმე კვლევას, მაშინ შეიძლება აღინიშნოს, რომ კვლევა და ანალიზი ექვემდებარება არა კვლევითი ობიექტის კომპლექტის ყველა ერთეულს. მხოლოდ მთელი რიგი მთელი რიგი ნაწილია გათვალისწინებული. ეს პროცესი ნიმუშია: როდესაც კომპლექტის მხოლოდ რამდენიმე ერთეული გამოძიებულია.
რა თქმა უნდა, ბევრად დამოკიდებულია შერჩევის ტიპზე. მაგრამ არსებობს ძირითადი წესები. მთავარია, რომ აგრეგატის შერჩევა აბსოლუტურად შემთხვევითი უნდა იყოს. AGGREGATE- ის ერთეული, რომელიც გამოყენებული იქნება ნებისმიერი კრიტერიუმის გამო. უხეშად საუბრობდა, თუ თქვენ უნდა შეაგროვოთ გარკვეული ქალაქის მოსახლეობის მთლიანი და მხოლოდ მამაკაცების აღება, მაშინ კვლევა იქნება შეცდომა, რადგან შერჩევა არ იყო შემთხვევით დახარჯული, მაგრამ გენდერული არჩეული. ამ წესით თითქმის ყველა ნიმუშის მეთოდი ეფუძნება.
შერჩევის წესები
შერჩეული აგრეგატისთვის მთელი ფენომენის ძირითადი თვისებების ასახვის მიზნით, უნდა აშენდეს კონკრეტული კანონების მიხედვით, სადაც აუცილებელია შემდეგი კატეგორიების ფოკუსირება:
- ნიმუში (შერჩევითი აგრეგატი);
- საერთო მოსახლეობა;
- წარმომადგენლობა;
- წარმომადგენლობითი შეცდომა;
- აგრეგატის ერთეული;
- ნიმუშის მშენებლობის მეთოდები.
მახასიათებლები შერჩევითი დაკვირვება და ნიმუში შედგება:
- მიღებული ყველა შედეგი ეფუძნება მათემატიკურ კანონებსა და წესებს, რაც არის სათანადო კვლევისა და სწორი გათვლებით, შედეგები არ იქნება დამახინჯებული სუბიექტური.
- ეს საშუალებას აძლევს ბევრად უფრო სწრაფად და ნაკლები დროისა და რესურსების მიღებას, რათა მიიღონ შედეგი, არ სწავლობენ მოვლენების მთელი მასივის, მაგრამ მხოლოდ მათი ნაწილი.
- ეს შეიძლება გამოყენებულ იქნას სხვადასხვა ობიექტების შესწავლაზე: კონკრეტული საკითხებიდან, მაგალითად, ასაკი, ჯგუფის სართული თქვენ დაინტერესებული ხართ, კვლევაში Საზოგადოებრივი აზრი ან მოსახლეობის მატერიალური მხარდაჭერის დონე.
შერჩევითი დაკვირვება
ნიმუში - ეს არის სტატისტიკური დაკვირვებარომელშიც შესწავლა არ ექვემდებარება სწავლის მთელ მთლიანობას, მაგრამ მხოლოდ გარკვეულწილად შერჩეული მისი ნაწილი, და ამ ნაწილის შესწავლის შედეგები მთელ კომპლექტში გადანაწილდება. ეს ნაწილი ეწოდება შერჩევითი კომპლექტი. ეს არის ერთადერთი გზა შესწავლის ობიექტის დიდი მასივის შესასწავლად.
მაგრამ შერჩევითი დაკვირვება შეიძლება გამოყენებულ იქნას მხოლოდ იმ შემთხვევებში, როდესაც აუცილებელია მხოლოდ ერთეულების მცირე ჯგუფის გამოძიება. მაგალითად, მსოფლიოსთვის ქალებისათვის მამაკაცების თანაფარდობის შესწავლისას გამოყენებული იქნება შერჩევითი დაკვირვება. აშკარა მიზეზების გამო, შეუძლებელია ჩვენი პლანეტის ყველა მკვიდრი.
მაგრამ იგივე კვლევა, მაგრამ არა დედამიწის ყველა მცხოვრებნი, მაგრამ კონკრეტულ სკოლაში, გარკვეული 2 "A" კლასი, გარკვეულ ქალაქს, გარკვეულ ქალაქს, შეუძლია გააკეთოს შერჩევითი დაკვირვების გარეშე. ყოველივე ამის შემდეგ, ანალიზი კვლევის ობიექტის მთელი მასივი - ეს შესაძლებელია. აუცილებელია ამ კლასის ბიჭების და გოგონების გამოთვლა - ეს იქნება თანაფარდობა.

შერჩევითი და ზოგადი აგრეგატი
სინამდვილეში, ყველაფერი ასე არ არის რთული, როგორც ჟღერს. ნებისმიერ ობიექტში სწავლისას, არსებობს ორი სისტემა: ზოგადი და შერჩევითი აგრეგატი. Რა არის ეს? ყველა ერთეული ზოგადად ეხება. და შერჩევით - იმ მთლიანი აგრეგატის ერთეული, რომელიც ნიმუშზე გადაიყვანეს. თუ ყველაფერი სწორად კეთდება, მაშინ შერჩეული ნაწილი იქნება მთელი (ზოგადი) კომპლექტის შემცირებული განლაგება.
თუ ვსაუბრობთ ზოგად აგრეგატზე, მაშინ მხოლოდ ორი ტიპის გამოირჩევა: გარკვეული და განუსაზღვრელი ზოგადი აგრეგატი. ეს დამოკიდებულია იმაზე, არის თუ არა ამ სისტემის ერთეულთა რაოდენობა ცნობილი თუ არა. თუ ეს არის გარკვეული ზოგადი კომპლექტი, მაშინ ნიმუში გააკეთებს ადვილია იმის გამო, თუ რა არის ცნობილი, თუ რომელი რაოდენობის ერთეულების რაოდენობა იქნება ნიმუში.
ეს მომენტი ძალიან აუცილებელია კვლევაში. მაგალითად, თუ თქვენ უნდა შეისწავლოთ კონკრეტული ქარხნის ცუდი ხარისხის საკონდიტრო ნაწარმის პროცენტული მაჩვენებელი. დავუშვათ, რომ ზოგადი აგრეგატი უკვე განსაზღვრულია. უბრალოდ ცნობილია, რომ წელიწადში ეს კომპანია 1000 საკონდიტრო ნაწარმს აწარმოებს. თუ ამ ათასამდე ათასიდან 100 შემთხვევითი საკონდიტრო ნაწარმის ნიმუშს გააკეთებთ და მათ გამოაგზავნოთ, შეცდომა იქნება მინიმალური. უხეშად საუბრობდა, კვლევა იყო ყველა პროდუქციის 10% -ს, ხოლო შედეგების შესახებ, ჩვენ შეგვიძლია გამოვყოთ წარმომადგენლობის შეცდომის გათვალისწინებით, ყველა პროდუქციის ცუდი ხარისხზე საუბარი.
და თუ თქვენ გაქვთ 100 საკონდიტრო ნაწარმის ნიმუში განუსაზღვრელი ზოგადი აგრეგატისგან, სადაც ისინი რეალურად, აღიარებულნი იყვნენ, 1 მილიონი ერთეული, ნიმუშის შედეგი და კვლევა თავად იქნება კრიტიკული და არასწორი. ფიქრობთ განსხვავება? აქედან გამომდინარე, ზოგადი მოსახლეობის რეალობა უმეტეს შემთხვევაში ძალიან მნიშვნელოვანია და მნიშვნელოვნად აისახება კვლევის შედეგს.

აგრეგატის წარმომადგენლობა
ასე რომ, ახლა ერთ-ერთი ყველაზე მნიშვნელოვანი საკითხია - რა უნდა იყოს ნიმუში? ეს არის კვლევის მთავარი მომენტი. ამ ეტაპზე აუცილებელია ნიმუშის გამოთვლა და შერჩეული ერთეული მთელი მასში. კომპლექტი სწორად შეირჩა, თუ ზოგადი მოსახლეობის გარკვეული თვისებები და მახასიათებლები შერჩევით რჩება. ეს ეწოდება წარმომადგენელს.
სხვა სიტყვებით რომ ვთქვათ, თუ შერჩევის შემდეგ, ნაწილი ინარჩუნებს იმავე ტენდენციებს და თვისებებს, რომლითაც გამოძიებული თანხა, მაშინ ასეთი კომპლექტი ეწოდება წარმომადგენელს. მაგრამ არა ყველა კონკრეტული ნიმუში შეიძლება შეირჩეს წარმომადგენლობითი მთლიანობით. კვლევის ასეთი ობიექტებია, რომლის ნიმუშიც არ შეიძლება იყოს წარმომადგენელი. აქედან და წარმომადგენლობის შეცდომის კონცეფცია ხდება. მაგრამ ჩვენ ამას უფრო მეტს ვსაუბრობთ.
როგორ გავაკეთოთ ნიმუში
ასე რომ, რომ წარმომადგენლობა მაქსიმალურია, სამი ძირითადი ნიმუშის წესების გამოყოფა:

შეცდომა (შეცდომა) წარმომადგენლობა
შერჩეული ნიმუშის ხარისხის ძირითადი მახასიათებელია "წარმომადგენლის შეცდომის" კონცეფცია. Რა არის ეს? ეს არის გარკვეული შეუსაბამობები შერჩევითი და მყარი დაკვირვების ინდიკატორებს შორის. შეცდომის თვალსაზრისით, წარმომადგენლობა დაყოფილია საიმედო, ჩვეულებრივი და სავარაუდო. სხვა სიტყვებით რომ ვთქვათ, დასაშვები გადახრები 3% -მდე, 3-დან 10% -მდე და 10-დან 20% -მდე. მიუხედავად იმისა, რომ სასურველია სტატისტიკაში, რომ შეცდომა არ აღემატება 5-6% -ს. წინააღმდეგ შემთხვევაში, არსებობს იმის მიზეზი, რომ ვისაუბროთ ნიმუშის არასაკმარისი წარმომადგენლობით. წარმომადგენლობის გადაუდებელობის გამოთვლა და როგორ მოქმედებს შერჩევითი ან ზოგადი მოსახლეობა, ბევრი ფაქტორი გათვალისწინებულია:
- ალბათობა, რომლითაც აუცილებელია ზუსტი შედეგის მიღება.
- შერჩევითი აგრეგატის ერთეულების რაოდენობა. როგორც ზემოთ აღინიშნა, ნაკლები ერთეული იქნება ნიმუში, უფრო დიდი იქნება წარმომადგენლობა შეცდომა და პირიქით.
- სწავლის ქვეშ მთლიანობის ერთიანობა. მეტი ჰეტეროგენული არის მთლიანობა, უფრო დიდი გაურკვევლობა წარმომადგენლობით. წარმომადგენლის აგრეგატის შესაძლებლობა დამოკიდებულია ყველა კომპონენტის ერთგვაროვნებაზე.
- ერთეულების შერჩევის მეთოდი შერჩევითი აგრეგატი.
კონკრეტულ კვლევებში, საშუალო შეცდომის პროცენტული მაჩვენებელი, როგორც წესი, მკვლევარმა თავად დაკვირვების პროგრამის საფუძველზე და ადრე ჩატარებული კვლევების მონაცემებით. როგორც წესი, მოქმედი შერჩევის შეცდომა ითვლება დასაშვები შეცდომა (წარმომადგენლობა) 3-5%.

მეტი - ყოველთვის არ არის უკეთესი
ასევე აღსანიშნავია, რომ შერჩევითი დაკვირვების ორგანიზებაში მთავარია, რომ მისი მოცულობა დასაშვები იყოს მინიმალური. არ უნდა იბრძვის შერჩევის შეცდომის საზღვრების გადაჭარბებული შემცირება, რადგან ეს შეიძლება გამოიწვიოს ამ ნიმუშების ზომის გაუმართლებელი ზრდა და, შესაბამისად, შერჩევითი დაკვირვების ხარჯების ზრდა.
ამავე დროს, შეუძლებელია, რომ ზედმეტად გაიზარდოს წარმომადგენლობის გადაუდებელი ზომა. მართლაც, ამ შემთხვევაში, მიუხედავად იმისა, რომ იქნება შერჩევითი აგრეგატის ოდენობის შემცირება, ეს გამოიწვევს მიღებული შედეგების სიზუსტის გაუარესებას.
რა კითხვები, როგორც წესი, განათავსეთ მკვლევართა წინაშე
ნებისმიერი კვლევა, თუ იგი ხორციელდება, შემდეგ გარკვეული მიზნით და გარკვეული შედეგების მისაღებად. ნიმუშის შესწავლისას, როგორც წესი, თავდაპირველი კითხვები დააყენა:

ნიმუშის კვლევის შერჩევის მეთოდები
არ არის ყველა ნიმუში წარმოდგენილია. ზოგჯერ იგივე ნიშანი ზოგადად ზოგადად ზოგადად და თავის ნაწილებში. წარმომადგენლობის მოთხოვნების მისაღწევად, მიზანშეწონილია სხვადასხვა შერჩევის მეთოდების გამოყენება. უფრო მეტიც, ერთი ან სხვა მეთოდის გამოყენება დამოკიდებულია კონკრეტულ გარემოებებზე. ამ ნიმუშის შექმნის ტექნიკას შორის გამოირჩევა:
- შემთხვევითი შერჩევა;
- მექანიკური შერჩევა;
- ტიპიური შერჩევა;
- სერიული (ბუდე) შერჩევა.
შემთხვევითი შერჩევა არის საერთო ზომების სისტემა, რომელიც მიზნად ისახავს აგრეგატის ერთეულების შემთხვევითი შერჩევისას, როდესაც ნიმუშის მიღების ალბათობა ზოგადი მოსახლეობის ყველა ერთეულს უდრის. მიზანშეწონილია გამოიყენოს ეს ტექნიკა მხოლოდ ჰომოგენურობის შემთხვევაში და მასში არსებულ მცირე რაოდენობას. წინააღმდეგ შემთხვევაში, ზოგიერთი დამახასიათებელი თვისებები არ აისახება ნიმუშში. შემთხვევითი შერჩევის ნიშნები ეფუძნება ყველა სხვა გზას ნიმუშის შესაქმნელად.
ერთეულების მექანიკური შერჩევა გარკვეული ინტერვალებით ხორციელდება. თუ კონკრეტული დანაშაულის ნიმუშის ჩამოყალიბება გჭირდებათ, შეგიძლიათ გაიყვანოთ რეგისტრირებული დანაშაულის ყველა სტატისტიკური საბუღალტრო აღრიცხვის ბარათებიდან თითოეული 5, მე -15 ან მე -15 ბარათის მიხედვით, რაც დამოკიდებულია მათი საერთო რაოდენობისა და ნიმუშის ზომაზე. ამ მეთოდის მინუსი ის არის, რომ შერჩევის დაწყებამდე აუცილებელია აგრეგატის ერთეულის სრული აღრიცხვა, შემდეგ კი რანჟირება და მხოლოდ ამის შემდეგ შესაძლებელია გარკვეული ინტერვალით ნიმუში. ეს მეთოდი დიდ დროს იღებს, ასე რომ, ხშირად არ გამოიყენება.

ტიპიური (Zoned) შერჩევა არის შერჩევის ტიპი, რომელშიც ზოგადი მოსახლეობა ერთგვაროვან ჯგუფებად დაყოფილია გარკვეულ ნიშანზე. ზოგჯერ მკვლევარები იყენებენ სხვა პირობებს ჯგუფების ნაცვლად: "ოლქები" და "ზონები". შემდეგ, თითოეული ჯგუფის შემთხვევითი წესით, გარკვეული რაოდენობის ერთეული შერჩეულია ჯგუფის კონკრეტული წონის პროპორციულად მთლიანი აგრეგატით. ტიპიური შერჩევა ხშირად ხორციელდება რამდენიმე ეტაპზე.
სერიული შერჩევა არის მეთოდი, რომელშიც ერთეული შერჩევა ხორციელდება ჯგუფების მიერ (სერია) და შერჩეული ჯგუფის ყველა ერთეული (სერია) ექვემდებარება კვლევას. ამ მეთოდის უპირატესობა ის არის, რომ ზოგჯერ ინდივიდუალური ერთეულების შერჩევა უფრო რთულია, ვიდრე სერია, მაგალითად, იმ პირის შესწავლისას, რომელიც სასჯელს იხდის. შერჩეული ტერიტორიების ფარგლებში, ზონებს ყველა ერთეულების შესწავლა გამონაკლისის გარეშე ვრცელდება, მაგალითად, ყველა კონკრეტულ დაწესებულებაში სასჯელის ყველა პირის შესწავლა.
შერჩევის ტიპები:
რეალურად შემთხვევითი;
მექანიკური;
Ტიპიური;
სერიალი;
კომბინირებული.
რეალურად შემთხვევითი ნიმუშიეს არის ზოგადი აგრეგატის ერთეულების შერჩევა შემთხვევითი, სისტემის ნებისმიერი ელემენტის გარეშე. თუმცა, თვითმმართველობის შემთხვევითი შერჩევის წარმოების დაწყებამდე აუცილებელია, რომ ზოგად მოსახლეობის ყველა ერთეული აბსოლუტურად თანაბარი შანსია ნიმუშში, არ არსებობს პასაჟები, ინდივიდუალური ერთეულების იგნორირება და მსგავსი. მან ასევე უნდა დაამყაროს საერთო მოსახლეობის მკაფიო საზღვრები ისე, რომ ინდივიდუალური ერთეულების ჩართვა ან ურთიერთქმედება არ იწვევს ეჭვებს. მაგალითად, სტუდენტების შესწავლისას აუცილებელია მიუთითოს თუ არა აკადემიური შვებულების მქონე პირები, არასახელმწიფო უნივერსიტეტების, სამხედრო სკოლების სტუდენტები და ა.შ. სავაჭრო საწარმოების შემოწმებისას მნიშვნელოვანია, რომ განვსაზღვროთ თუ არა ზოგადი აგრეგატი, რომელიც მოიცავს სავაჭრო პავილიონებს, კომერციულ კარვებში და სხვა მსგავსი ობიექტებს. თვითმმართველობის შემთხვევითი შერჩევა შეიძლება იყოს განმეორებითი და რეპუტაცია. ნახაზის პროცესში შერჩევის შესაწირავების შესასწავლად, ორიგინალური კომპლექტში დაბრუნება არ დაბრუნდება და მომავალში შერჩევა არ არის ჩართული. შემთხვევითი ნომრების ცხრილების გამოყენებისას, ინტეგრციის მაჩვენებელი მიღწეულია მათ მიერ შერჩეული სვეტის ან სვეტების განმეორების შემთხვევაში.
მექანიკური ნიმუშიგამოიყენება იმ შემთხვევებში, როდესაც ზოგადი მოსახლეობა არანაირად არის შეკვეთილი, ანუ. არსებობს გარკვეული თანმიმდევრობა ერთეულების ადგილას (თანამშრომელი ტაბლეტები, ამომრჩეველთა სიები, მოპასუხე ნომრები, სახლები და ბინები და ა.შ.).
მექანიკური შერჩევის ზოგადი კომბინაცია შეიძლება იყოს ადგილზე ან გამარტივდეს მასთან ნიშნის ან კორელაციის მასშტაბით, რომელიც გაზრდის ნიმუშის წარმომადგენლობას. თუმცა, ამ შემთხვევაში, სისტემატური შეცდომის რისკი იზრდება, რომელიც დაკავშირებულია ატრიბუტის ღირებულებების შემსწავლელთან შედარებით (თუ პირველი ღირებულება ჩაწერილია თითოეული ინტერვალით) ან მისი გადაჭარბება (თუ ეს უკანასკნელი ღირებულება ჩაწერილია თითოეული ინტერვალით). აქედან გამომდინარე, მიზანშეწონილია პირველი ინტერვალის შუაგულში დაწყებული
ტიპიური შერჩევა.ეს შერჩევის მეთოდი გამოიყენება იმ შემთხვევებში, როდესაც ზოგადი მოსახლეობის ყველა ერთეული შეიძლება დაიყოს რამდენიმე ტიპიურ ჯგუფად. მოსახლეობის გამოკვლევისას, ასეთი ჯგუფები შეიძლება იყოს, მაგალითად, ტერიტორიები, სოციალური, ასაკი ან საგანმანათლებლო ჯგუფები, საწარმოების კვლევის დროს - ფილიალი ან ქვედანაყოფი, საკუთრების ფორმა და ა.შ. ტიპიური შერჩევა მოიცავს თითოეული ტიპური ჯგუფის ნიმუშის ნიმუშს შემთხვევითი ან მექანიკური გზით. ერთი ჯგუფების წარმომადგენლები ერთ ან სხვა პროპორციით, ყველა ჯგუფის წარმომადგენლები, ერთ ჯგუფში, ერთ-ერთში, ითხოვენ, ზოგადი მოსახლეობის აკრეფა საშუალებას იძლევა, გააუქმოს INTERGROUP დისპერსიის ეფექტი საშუალო შერჩევის შეცდომის შესახებ, რომელიც ეს საქმე განისაზღვრება მხოლოდ IntraGroup ვარიაციით.
ტიპიური ნიმუშის ერთეულების შერჩევა შეიძლება ორგანიზებული ან ტიპიური ჯგუფების მოცულობის პროპორციულად, ან ფუნქციის ინტრარატის დიფერენცირების პროპორციულად.
სერიული შერჩევა.შერჩევის ეს მეთოდი მოსახერხებელია იმ შემთხვევებში, როდესაც მთლიანობა მცირე ჯგუფებში ან სერიაში შედის. როგორც ასეთი სერია, შეფუთვა გარკვეული რაოდენობის მზა პროდუქტთან, საქონლის, სტუდენტური ჯგუფების, ბრიგადებისა და სხვა ასოციაციების სახით შეიძლება ჩაითვალოს. სერიული ნიმუშის არსი მდგომარეობაშია სერიის შემთხვევითი ან მექანიკური შერჩევისას, რომლის ფარგლებშიც არის ერთეული მყარი კვლევა.
ემპირიული განიხილება სოციალური ურთიერთობების და პროცესების შესწავლის ერთ-ერთი მთავარი საშუალება. ისინი უზრუნველყოფენ საიმედო, სრული და წარმომადგენლობითი ინფორმაციას.
ტექნიკის სპეციფიკა
ემპირიული ცოდნა ფაქტობრივ ცოდნას. ისინი ხელს უწყობენ ურთიერთობების დამყარების ან პირდაპირი რეგისტრაციის ხარჯების დაფუძნებასა და განზოგადებას, რომლებიც სწავლობენ ობიექტებს, ფენომენას. ემპირიული ტექნიკა განსხვავდება თეორიული ფაქტიდან, რომ ანალიზის თემაა:
- ფიზიკური პირების ქცევა და მათი ჯგუფები.
- ადამიანის საქმიანობა.
- პირების სიტყვიერი ქმედებები, მათი გადაწყვეტილებები, შეხედულებები, მოსაზრებები.
ნიმუშის კვლევები
ემპირიული სწავლება ყოველთვის არის ორიენტირებული ობიექტური და ზუსტი ინფორმაციის მოპოვების, რაოდენობრივი მონაცემების მოპოვებაზე. ამ თვალსაზრისით, როდესაც იგი შესრულებულია, აუცილებელია ინფორმაციის წარმოსახვის უზრუნველსაყოფად. შესაბამისად, სწორი მნიშვნელობა სწორია შერჩევითი აგრეგატი. ის ეს იმას ნიშნავს, რომ შერჩევა უნდა განხორციელდეს ისე, რომ ვიწრო ჯგუფის მიღებული მონაცემები ასახავს ტენდენციებს, რომლებიც ჩატარდება რესპონდენტთა საერთო მასში. მაგალითად, 200-300 ადამიანზე გამოკვლევისას, მიღებული მონაცემები შეიძლება იყოს ექსტრაპოლაცია ყველა ურბანული მოსახლეობა. შერჩევითი აგრეგატის მაჩვენებლები საშუალებას მისცემს სხვადასხვა მიდგომას რეგიონში სოციალურ-ეკონომიკური პროცესების შესწავლას მთელი ქვეყნის მასშტაბით.

ტერმინოლოგია
შერჩევითი კვლევისთან დაკავშირებული საკითხების უკეთ გაგება, აუცილებელია გარკვეული განმარტებების გასარკვევად. დაკვირვების ერთეული არის ინფორმაციის პირდაპირი წყარო. ისინი შეიძლება იყოს ცალკე ინდივიდუალური, ჯგუფი, დოკუმენტი, ორგანიზაცია და ასე შემდეგ. ზოგადი აგრეგატი არის დაკვირვების კომპლექსი. ისინი უნდა იყოს დაკავშირებული იმ პრობლემასთან, რომელიც შესწავლილია. პირდაპირი ანალიზი ექვემდებარება. კვლევა ხორციელდება ინფორმაციის შეგროვებისათვის განვითარებული მეთოდების შესაბამისად. რათა დადგინდეს რესპონდენტთა მთელი მასივის ამ წილის გამოყენება "შერჩევითი აგრეგატის" კონცეფცია. მისი ქონება ასახავს ხალხის საერთო მასის ძირითად პარამეტრებს წარმომადგენლობას. ზოგიერთ შემთხვევაში შემთხვევითი არ არის. შემდეგ ისინი საუბრობენ წარმომადგენლობის შეცდომაზე.
რომელიც უზრუნველყოფს წარმომადგენლობას
მასთან დაკავშირებული საკითხები სტატისტიკის ფარგლებში განიხილება. პრობლემები გამოირჩევა სირთულეებით, რადგან, ერთის მხრივ, შემოთავაზებულია რაოდენობრივი წარმომადგენლობა, რომელიც იძლევა საერთო მოსახლეობა. ის მიუთითებს, კერძოდ, რესპონდენტთა ჯგუფები უნდა იყოს წარმოდგენილი ოპტიმალური რიცხვით. რაოდენობა უნდა იყოს საკმარისი ნორმალური წარმომადგენლობისთვის. მეორეს მხრივ, არსებობს ასევე თვისებრივი წარმომადგენლობა. იგი მოიცავს გარკვეულ სუბიექტს, რომელიც ჩამოყალიბებულია შერჩევითი აგრეგატი. ის ეს იმას ნიშნავს, რომ, მაგალითად, წარმომადგენლობა არ შეიძლება განიხილებოდეს, თუ მხოლოდ მამაკაცები გამოკითხულნი არიან ან მხოლოდ ქალები, ხანდაზმული ადამიანები ახალგაზრდები. კვლევა უნდა განხორციელდეს ყველა წარმოდგენილი ჯგუფში.

დამახასიათებელი ნიმუში
ეს ტერმინი ითვლება ორ ასპექტში. უპირველეს ყოვლისა, განისაზღვრება, როგორც ადამიანების საერთო მასივის ელემენტების კომპლექსი, რომელთა აზრიც სწავლობს - ეს შერჩევითი აგრეგატი. ის გარდა ამისა, რესპონდენტების კონკრეტული კატეგორიის შექმნის პროცესი წარმომადგენლობისთვის აუცილებელი დებულებით. პრაქტიკაში, რამდენიმე ტიპის და შერჩევის სახეები გამოირჩევა. განვიხილოთ ისინი.
სახეები
სამი მათგანია:
- სტიქიური შერჩევითი აგრეგატი. ის მოხალისეობის პრინციპზე შერჩეული რესპონდენტების კომპლექტი. ამავდროულად, უზრუნველყოფილია კონკრეტული სასწავლო ჯგუფის მთლიანი მასის ერთეულების ხელმისაწვდომობა. სპონტანური შერჩევა პრაქტიკაში საკმაოდ ხშირად გამოიყენება. მაგალითად, პრესაში პრესაში, ფოსტით. თუმცა, ეს ტექნიკა მნიშვნელოვანი ნაკლოვანია. შეუძლებელია ზოგადი ნიმუშის მთლიანი თანხა. ეს ტექნიკა გამოიყენება ეკონომიკის საფუძველზე. ზოგიერთ გამოკითხვაში ეს ვარიანტი ერთადერთი შესაძლებელია.
- სტიქიური შერჩევითი აგრეგატი. ის კვლევაში გამოყენებული ერთ-ერთი მთავარი ტექნიკა. როგორც ასეთი შერჩევის ძირითადი პრინციპი, შესაძლებელია თითოეული სადამკვირვებლო ერთეულის შესაძლებლობების უზრუნველსაყოფად ვიწრო ჯგუფში ადამიანების საერთო მასიდან. ეს იყენებს სხვადასხვა ტექნიკას. მაგალითად, ეს შეიძლება იყოს ლატარიის, მექანიკური შერჩევა, შემთხვევითი რიცხვების მაგიდა.
- სტრატიფიცირებული (Quarry) ნიმუში. იგი ეფუძნება რესპონდენტთა საერთო მასის თვისებრივი მოდელის ჩამოყალიბებას. ამის შემდეგ, შერჩევა ერთეული ხორციელდება შერჩევითი მთლიანობაში. მაგალითად, იგი ასაკისა თუ სქესის მიხედვით ხორციელდება მოსახლეობის მიხედვით და ასე შემდეგ.
Დათვალიერება
არსებობს შემდეგი ნიმუშები:

გარდა ამისა
ნიმუშები შეიძლება იყოს დამოკიდებული და დამოუკიდებელი. პირველ შემთხვევაში, ექსპერიმენტული პროცედურა და შედეგები, რომლებიც მიიღებენ რესპონდენტთა ერთ ჯგუფს, მასზე გარკვეული გავლენა აქვთ. შესაბამისად, დამოუკიდებელი ნიმუშები არ აპირებს ასეთი გავლენა. აქ, თუმცა, ყურადღება უნდა მიაქციოთ ერთ მნიშვნელოვან პუნქტს. სუბიექტების ერთ-ერთი ჯგუფი, რომელთა მიმართაც ფსიქოლოგიური ექსპერტიზა ორჯერ ჩატარდა (მაშინაც კი, თუ ის მიზნად ისახავდა სხვადასხვა თვისებების, თვისებების, თვისებების შესწავლას), ნაგულისხმევი დამოკიდებული იქნება დამოკიდებული.
Probabilistic Selections
განვიხილოთ ზოგიერთი ტიპის ნიმუშები:
- შემთხვევითი. იგი მოიცავს მთლიანი აგრეგატის ჰომოგენურობას, ყველა კომპონენტის ხელმისაწვდომობის ალბათობას, ისევე როგორც ელემენტების სრული სიის არსებობას. როგორც წესი, მაგიდა შემთხვევითი ნომრებით გამოიყენება შერჩევისას.
- მექანიკური. ამ ტიპის შემთხვევითი შერჩევა გულისხმობს კონკრეტულ ფუნქციას. მაგალითად, ტელეფონის ნომრით, ანბანის მიხედვით, დაბადების თარიღით და ასე შემდეგ. პირველი კომპონენტი არჩეულია შემთხვევითი წესით. შემდეგი, შერჩევა თითოეული K ელემენტის ნაბიჯი n. საერთო აგრეგატის მასშტაბები იქნება n \u003d k * n.
- Strattic. ეს ნიმუში გამოიყენება მთლიანი აგრეგატის ინჰომოგენურობაში. ეს უკანასკნელი დაყოფილია ფლათაში (ჯგუფები). თითოეულ მათგანს, შერჩევა ხორციელდება მექანიკური ან შემთხვევითი გზით.
- სერიალი. ჯგუფის შერჩევა შემთხვევითია. მათ შიგნით, ობიექტები შესწავლილია მყარი.
დაუჯერებელი არჩევანი
ისინი გვთავაზობენ ნიმუშს, რომ არ იყოს შანსის პრინციპი, მაგრამ სუბიექტური ნიშნების მიხედვით: ტიპიური, ხელმისაწვდომობა, თანაბარი წარმომადგენლობა და ასე შემდეგ. ამ კატეგორიაში შედის არჩევანი:

Nuance
წარმომადგენლობის უზრუნველსაყოფად, საჭიროა აგრეგატის ერთეულების ზუსტი და სრული სია. დაკვირვების ობიექტები, როგორც წესი, ერთი ადამიანია. სიიდან შერჩევა უკეთესია, განახორციელოს, ნუმერაციის ერთეული და მაგიდის გამოყენება შემთხვევითი ნომრებით. მაგრამ quasonicound მეთოდი ხშირად გამოიყენება საკმაოდ ხშირად. ეს გულისხმობს თითოეული N ელემენტის სიიდან შერჩევას.
გავლენას ახდენს ფაქტორები
აგრეგატის მოცულობა ეწოდება თავის ერთეულებს. ექსპერტების აზრით, ეს არ უნდა იყოს დიდი. ეჭვგარეშეა, სხვა ნომერი რესპონდენტები, უფრო ზუსტი შედეგი. თუმცა, ამით, დიდი თანხა ყოველთვის არ იძლევა წარმატებას. მაგალითად, ეს მოხდება, როდესაც რესპონდენტთა საერთო მასივი არაფორია. ერთგვაროვანია ასეთი კომბინაცია, სადაც კონტროლირებადი პარამეტრი, მაგალითად, წიგნიერების მაჩვენებელი თანაბრად გადანაწილდება, ანუ, არ არსებობს სიცარიელე ან გასქელება. ამ შემთხვევაში, საკმარისი იქნება რამდენიმე ადამიანისთვის გასაუბრება. კვლევის შედეგების მიხედვით, შესაძლებელი იქნება დავასკვნათ, რომ ადამიანების უმრავლესობას ნორმალური წიგნიერების მაჩვენებელი აქვს. აქედან გამომდინარე, ინფორმაციის გავლენა არ არის რაოდენობრივი ნიშნები, მაგრამ აგრეგატის თვისებრივი მახასიათებლები მისი ჰომოგენურობის დონეა, კერძოდ.

შეცდომები
ისინი წარმოადგენენ რესპონდენტთა საერთო მასის ღირებულებებზე ნიმუშის საშუალო პარამეტრების გადახრას. პრაქტიკაში, შეცდომები განისაზღვრება შედარებით. მოზრდილების შემოწმებისას, კორესპონდენცია, სტატისტიკური აღრიცხვა, ისევე როგორც წარსული კვლევების შედეგები. კონტროლის პარამეტრების ჩვეულებრივ ასრულებს აგრეგატების საშუალო კომპლექტების შედარება (ზოგადი და შერჩევითი), განსაზღვრავს ამ შეცდომის მიხედვით და ამ დეფლექციის შემცირება არის წარმოდგენილი, როგორც წარმომადგენლობა.
დასკვნები
შერჩევითი კვლევა არის რესპონდენტების სპეციალურად შერჩეული ჯგუფების კვლევის გზით მონაცემთა შეგროვების მონაცემების შეგროვების მეთოდი. ეს მიღება ითვლება საიმედო და ეკონომიურ, თუმცა ეს მოითხოვს ზოგიერთ ტექნიკას. ბაზა არის შერჩევითი კომპლექტი. იგი მოქმედებს ხალხის მთლიანი მასალის გარკვეული ნაწილი. შერჩევა სპეციალურ ტექნიკას იყენებს და მიზნად ისახავს მთლიანი მთლიანობის შესახებ ინფორმაციის მიღებას. ეს უკანასკნელი, თავის მხრივ, წარმოდგენილია ყველა შესაძლო საჯარო ობიექტით ან ჯგუფის მიერ, რომელიც შესწავლილია. ხშირად, ზოგადი აგრეგატი იმდენად დიდია, რომ თითოეული წარმომადგენლის კვლევა საკმაოდ ძვირია და მძიმე პროცესია. ამიტომ, მისი შემცირებული მოდელი გამოიყენება. შერჩევით კომპლექტში, ყველა მათგანი, ვინც კითხვარების მიღებას იღებენ, რომლებიც მოიხსენიებენ რესპონდენტებს, რომლებიც რეალურად მოქმედებენ სწავლის ობიექტად. მარტივად რომ ვთქვათ, ის ბევრ ადამიანს წარმოადგენს, რომლებიც გამოკითხულნი არიან.

დასკვნა
კვლევის მიზნები განისაზღვრება ზოგადი მოსახლეობის სპეციფიკურ კატეგორიებში. რაც შეეხება ხალხის მთლიანი მასალის კონკრეტულ წილს, მასემატიკური გათვლების დახმარებით ჯგუფებში შედის სუბიექტებს. ერთეულის შერჩევისთვის აუცილებელია ორიგინალური კომპლექტის ობიექტის აღწერა. სუბიექტების რაოდენობის განსაზღვრის შემდეგ განისაზღვრება ფორმირების ჯგუფების მიღება ან მეთოდი. კვლევის შედეგები საშუალებას მისცემს შეისწავლონ შესწავლილი ნიშანი ხალხის მთლიანი მასალის ყველა წარმომადგენლის შესახებ. როგორც პრაქტიკა შოუები, შერჩევითი და არა მყარი კვლევები ხორციელდება.
ნიმუშის გეგმის შედგენის პროცედურა მოიცავს სამი შემდეგი ამოცანის თანმიმდევრული გადაწყვეტა:
კვლევის ობიექტის განსაზღვრა;
შერჩევის სტრუქტურის განსაზღვრა;
შერჩევის განსაზღვრა.
ჩვეულებრივ, ობიექტის მარკეტინგული კვლევა ეს არის სადამკვირვებლო ობიექტების კომბინაცია, რომელიც მომხმარებელს, კომპანიის თანამშრომლებს, შუამავლებს და ა.შ. თუ ეს ტოტალია იმდენად მცირეა, რომ კვლევის გუნდს აქვს საჭირო შრომა, ფინანსური და დროებითი შესაძლებლობები, რათა თითოეული ელემენტის კონტაქტის დამყარება, საკმაოდ რეალისტურია, რომ მთელი მოსახლეობის უწყვეტი შესწავლა. ამ შემთხვევაში, კვლევის ობიექტის განსაზღვრისას შეგიძლიათ გააგრძელოთ შემდეგი პროცედურა (მონაცემთა შეგროვების მეთოდის არჩევანი, კვლევის ინსტრუმენტი და აუდიტორიასთან კომუნიკაციის მეთოდი).
თუმცა, პრაქტიკაში ძალიან ხშირად არ არის შესაძლებელი ან სათანადოდ, მთელი მოსახლეობის უწყვეტი შესწავლა. ამისათვის შეიძლება არსებობდეს შემდეგი მიზეზები:
მთლიანობის გარკვეულ ელემენტებთან კონტაქტის შეუძლებლობა;
არაგონივრულად დიდი ხარჯების ჩატარების მყარი კვლევის ან ფინანსური შეზღუდვების ხელმისაწვდომობა, რომელიც არ იძლევა მყარი კვლევის საშუალებას;
ინფორმაციის ან სხვა მიზეზების მიხედვით, კვლევისთვის გამოყოფილი ვადები გამოყოფილი ვადები და სხვა მიზეზების გამო დაკარგვის გამო და მთლიანი მთლიან მონაცემების შეგროვების, სისტემატიზაციისა და ანალიზის ანალიზისთვის.
აქედან გამომდინარე, დიდი და მიმოფანტული აგრეგატები ხშირად სწავლობენ შერჩევით, რომლის მიხედვითაც, როგორც ცნობილია, აგრეგატის ნაწილი გვხვდება მთლიანი მთლიანობის გასაკეთებლად.
სიზუსტე, რომელთანაც ნიმუში ასახავს მთელ მთლიანობას, რაც დამოკიდებულია შერჩევის სტრუქტურები და ზომა.
განასხვავებს ორ მიდგომას შერჩევის სტრუქტურას - Probabilistic და Deterministic.
სტაბილური მიდგომა შერჩევის სტრუქტურაში იგი მიიჩნევს, რომ აგრეგატის ნებისმიერი ელემენტი შეიძლება შეირჩეს გარკვეული (არა ნულოვანი) ალბათობით. არსებობა განსხვავებული სახეობები ნიმუშები საფუძველზე ალბათობის თეორია (ტიპიური, nesting და ა.შ.). მარტივი და საერთო პრაქტიკაში არის მარტივი შემთხვევითი ნიმუში, რომელშიც თითოეული ელემენტის აგრეგატი აქვს თანაბარი არჩევანი სასწავლო.
Probabilistic ნიმუში უფრო ზუსტია, საშუალებას აძლევს მკვლევარს შეაფასოს მის მიერ შეგროვებული მონაცემების საიმედოობის ხარისხი, თუმცა ეს უფრო რთული და უფრო ძვირია, ვიდრე განმსაზღვრელი.
განსაზღვრული მიდგომა ნიმუშის სტრუქტურას იგი მიიჩნევს, რომ კომპლექტის ელემენტების არჩევანი ხდება მეთოდებით, რომელიც დაფუძნებულია კომფორტის მოსაზრებებზე ან მკვლევარის ან კონტინგენტის ჯგუფებზე.
მოსაზრებებიიგი შედგება აგრეგატის ნებისმიერი ელემენტის არჩევისას მათთან კონტაქტის კონტაქტის სიმარტივის საფუძველზე. ამ მეთოდის არასრულყოფილება გამოწვეულია მიღებული ნიმუშის დაბალი წარმომადგენლობით, რადგან მკვლევართათვის საერთო აგრეგატის კომფორტული ელემენტები არ შეიძლება იყოს საკმარისად დამახასიათებელი წარმომადგენელი არა-შემთხვევითი და არაგონივრული შერჩევის გამო.
თუმცა, მეორე მხრივ, ამ მეთოდით ჩატარებული კვლევის სიმარტივე, ეფექტურობა და ეფექტურობა პრაქტიკაში საკმაოდ ფართოდ გავრცელდა და, უპირველეს ყოვლისა, წინასწარი კვლევების ჩატარებისას ძირითადი პრობლემების გასარკვევად.
შერჩევის ფორმირების მეთოდი დაფუძნებული მკვლევართა გადაწყვეტილებითიგი შედგება აგრეგატის ელემენტების არჩევისას, რაც თავის აზრით, მისი დამახასიათებელი წარმომადგენლები არიან. ეს მეთოდი უფრო სრულყოფილია, ვიდრე წინა, რადგან იგი ეფუძნება ორიენტაციის ორიენტაციის დამახასიათებელ წარმომადგენლებს, თუმცა შერჩეული მკვლევართა სუბიექტური წარმომადგენლობების საფუძველზე.
შერჩევის მეთოდი საფუძველზე კონტინგენტის სტანდარტებიიგი შედგება აგრეგატის დამახასიათებელი ელემენტების არჩევისას ადრე მიღებული აგრეგატის მახასიათებლების შესაბამისად. ეს მახასიათებლები შეიძლება მიღებული იქნას წინასწარი კვლევების ჩატარებით და წინა მეთოდისგან განსხვავებით, არ ატარებს სუბიექტურ ბუნებას. აქედან გამომდინარე, ეს მეთოდი უფრო სრულყოფილია, ეს საშუალებას გაძლევთ აირჩიოთ არანაკლებ წარმომადგენელი არანაკლებ წარმომადგენელი, ვიდრე ალბათობა ნაკლებად სათვალთვალო ხარჯებით.
შერჩევა ნიმუში სტრუქტურა (მიდგომა მისი ფორმირების, ტიპის probabilistic ან მოძრავი ფორმირების განმსაზღვრელი ნიმუშის), მკვლევარს მოუწევს განსაზღვროს მოცულობა, I.E. შერჩევითი აგრეგატის ელემენტების რაოდენობა.
შერჩევის მოცულობა განსაზღვრავს ინფორმაციის სიზუსტესმიღებული კვლევის შედეგად, ასევე კვლევის ჩატარებისათვის აუცილებელი ხარჯები. ნიმუშის ზომა დამოკიდებულია შესწავლილი ჰომოგენურობის დონე ან ობიექტების ჯიშები.
ნიმუშის ზომა, უმაღლესი მისი სიზუსტე და მისი კვლევისთვის უფრო მაღალი ხარჯები. ნიმუშების სტრუქტურის ალბათობა, მისი მოცულობა შეიძლება განისაზღვროს ცნობილი სტატისტიკური ფორმულების გამოყენებით, რომელიც ეფუძნება მის სიზუსტეს მითითებულ მოთხოვნებს.
პრაქტიკაში, შერჩევისას რამდენიმე მიდგომა გამოიყენება:
1. თვითნებური მიდგომა საფუძველზე გამოყენების "წესები thumb". მაგალითად, არ არის აუცილებელი, რომ ნიმუში უნდა იყოს მთლიანი რაოდენობის 5% ზუსტი შედეგების მისაღებად. ეს მიდგომა მარტივია და ადვილად ასრულებს, მაგრამ შეუძლებელია მიღებული შედეგების სიზუსტე. საკმარისად დიდი მთლიანობა, ეს შეიძლება იყოს ძალიან ძვირი.
ნიმუშის ზომა შეიძლება შეიქმნას გარკვეული წინასწარ განსაზღვრული პირობების საფუძველზე. მაგალითად, მარკეტინგული კვლევის მომხმარებელს იცის, რომ საზოგადოებრივი აზრის შესწავლისას, ნიმუში ჩვეულებრივ 1000-1200 ადამიანია, ამიტომ ის რეკომენდაციას აძლევს მკვლევარს ამ ფიგურის დაცვაში. იმ შემთხვევაში, თუ ყოველწლიურ კვლევებში გარკვეული ბაზარზე ტარდება, მაშინ ყოველწლიურად იყენებს იგივე მოცულობის ნიმუშს. პირველი მიდგომისგან განსხვავებით, ცნობილი ლოგიკა გამოიყენება აქ ნიმუშის მოცულობის განსაზღვრაში, რომელიც, თუმცა, ძალიან დაუცველია.
მაგალითად, გარკვეული კვლევების ჩატარებისას, სიზუსტე შეიძლება საჭირო იყოს საზოგადოებრივი აზრის შესწავლისას და საერთო ჯამში, საზოგადოებრივი აზრის შესწავლისას ბევრჯერ შეიძლება იყოს. ამდენად, ეს მიდგომა არ ითვალისწინებს მიმდინარე პირობებს და შეიძლება საკმაოდ ძვირი იყოს.
ზოგიერთ შემთხვევაში, როგორც მთავარი არგუმენტი, ნიმუშის მოცულობის განსაზღვრისას გამოიყენება კვლევის ღირებულება. ამრიგად, მარკეტინგული კვლევის ბიუჯეტი ითვალისწინებს გარკვეულ კვლევებს, რომლებიც არ უნდა აღემატებოდეს. ცხადია, მიღებული ინფორმაციის ღირებულება არ არის გათვალისწინებული. თუმცა, ზოგიერთ შემთხვევაში, მცირე ნიმუში შეიძლება საკმაოდ ზუსტი შედეგები.
როგორც ჩანს, გონივრულია, რომ არ გაითვალისწინოს აბსოლუტური გზა, მაგრამ კვლევების შედეგად მიღებული ინფორმაციის სარგებლობასთან დაკავშირებით. მომხმარებელმა და მკვლევარმა უნდა განიხილონ სხვადასხვა ნიმუშის მოცულობები და მონაცემთა შეგროვების მეთოდები, ხარჯები, გაითვალისწინონ სხვა ფაქტორები
2. ნიმუშის ზომა სწორი შეცდომის კონფიდენციალური ინტერვალის დონეზე, რა, როგორც უკვე აღვნიშნეთ, მოცემულია საბოლოო განზოგადების მიზანშეწონილობის სიზუსტით: გაიზარდა სავარაუდო. თუმცა, არსებობს გათვალისწინებული ე.წ. შემთხვევითი შეცდომები ასოცირდება ბუნების ნებისმიერი სტატისტიკური შეცდომები. ისინი გამოითვლება, როგორც პროგნოზირებული ნიმუშების წარმომადგენლობების შეცდომები.
V.i. Paniotto მოჰყავს წარმომადგენლობითი ნიმუშის შემდეგი გათვლები 5% -ით შეცდომის ნებართვით (ცხრილი 4.2).
ცხრილი 4.2.
გათვლილი ნიმუში მაგიდა
100 000-ზე მეტი ნიმუშის კომბინაციისთვის 400 ერთეულია. თუ გაითვალისწინე ზოგადი კომპლექტი 5 ათასი და მეტი, მაშინ, იმავე ავტორის გათვლებით, შეგიძლიათ განსაზღვროთ ნიმუშის ფაქტობრივი შეცდომების ღირებულებები, რაც დამოკიდებულია მის მოცულობაზე, რაც ძალიან მნიშვნელოვანია ჩვენთვის, გავიხსენოთ, რომ სწორი შეცდომის ღირებულება დამოკიდებულია კვლევისა და სურვილისამებრ უნდა მიაღწიოს 5 პროცენტს.
ცხრილი 4.3.
გამოითვლება მაგიდა
|
შერჩევა, თუ ზოგადი აგრეგატი 5000 | ||||||||
|
ფაქტობრივი შეცდომა ამ ნიმუშის მოცულობაში,% |
შემთხვევითი, სისტემური შეცდომების გარდა. ისინი დამოკიდებულია შერჩევითი გამოკვლევის ორგანიზებაზე. ეს არის მრავალფეროვანი შერჩევის ოფსეტური შერჩევითი პარამეტრის ერთ-ერთი პოლუსების მიმართ.
3. სტატისტიკური ანალიზის საფუძველზე შერჩევა . ეს მიდგომა ეფუძნება მინიმალური შერჩევის განსაზღვრას შედეგების საიმედოობისა და საიმედოობის საფუძველზე. იგი ასევე გამოიყენება ინდივიდუალური ქვეჯგუფებისთვის მიღებული შედეგების ანალიზში, რომელიც შეიქმნა შერჩევისას, ასაკში, ასაკში, განათლების დონეზე და ა.შ. ინდივიდუალური ქვეჯგუფების შედეგების საიმედოობისა და სიზუსტის მოთხოვნები, რომლებიც გარკვეულ მოთხოვნებს აკონტროლებენ ნიმუშის ზომაზე.
ნიმუშის მოცულობის განსაზღვრის ყველაზე თეორიულად დასაბუთებული და სწორი მიდგომა ეფუძნება საიმედო ინტერვალების გაანგარიშებას. ვარიაციის კონცეფცია ახასიათებს რესპონდენტთა არასწორი (მსგავსი) რეაგირების მასშტაბებს. უფრო მკაცრი გეგმის მიხედვით, კომპლექტში ნებისმიერი ნიშნის ღირებულებების ვარიაცია ეწოდება განსხვავებას ამ იმავე პერიოდში ან დროის სხვადასხვა ერთეულებისგან. კვლევის კითხვებზე რეაგირება, როგორც წესი, წარმოდგენილია სადისტრიბუციო მრუდის სახით (ნახ. 4.1). მაღალი მსგავსებით, პასუხები საუბრობენ დაბალი ვარიაციების შესახებ (ვიწრო განაწილების მრუდი) და დაბალი მსგავსების მსგავსებით - მაღალი ვარიაციის შესახებ (ფართო განაწილების მრუდი).
როგორც ვარიაციის ღონისძიება, საშუალო კვადრატული გადახრა ჩვეულებრივ აღებულია, რაც გარკვეულ კითხვაზე თითოეული რესპონდენტის რეაგირების საშუალო შეფასების საშუალო მანძილს ახასიათებს.
მცირე ვარიაცია
მაღალი ვარიაცია
ნახაზი. 4.1. ვარიაცია და განაწილების მოსახვევებში
მას შემდეგ, რაც ყველა მარკეტინგული გადაწყვეტილებები მიიღება გაურკვევლობაში, ეს გარემოება მიზანშეწონილია, რათა გაითვალისწინოს ნიმუშის ზომის განსაზღვრისას. ვიწრო კომპლექტში შესწავლილი ღირებულებების განმარტება ხორციელდება შერჩევითი სტატისტიკის საფუძველზე, უნდა იყოს შერჩეული სტატისტიკის საფუძველზე, დიაპაზონი (ნდობის ინტერვალი) უნდა იყოს მითითებული, რაც სავარაუდოდ მთლიანი მთლიანობის შეფასებას ითვალისწინებს და მათი განმარტების შეცდომა.
ნდობის ინტერვალი არის დიაპაზონი, რომელთა უკიდურესი წერტილები გარკვეულ კითხვებზე გარკვეული პასუხების გარკვეულ პროცენტებს შეესაბამება. ნდობის ინტერვალი მჭიდროდ არის დაკავშირებული ზოგადი მოსახლეობის შესწავლილი ატრიბუტის საშუალო კვადრატულ გადახრასთან: უფრო მეტად, უფრო ფართო ნდობის ინტერვალი უნდა იყოს, რათა შეიცავდეს პასუხების გარკვეულ პროცენტულ მაჩვენებელს.
ნდობის ინტერვალი, ტოლი ან 95%, ან 99%, არის მარკეტინგული კვლევის ჩატარება. არცერთი ფირმა არ ახორციელებს მარკეტინგის კვლევას რამდენიმე ნიმუშის ჩამოყალიბებით. მათემატიკური სტატისტიკა საშუალებას იძლევა გარკვეული ინფორმაციის მიღება შერჩევითი განაწილების შესახებ, მხოლოდ ერთი ნიმუშის ვარიაციების შესახებ.
შეფასების შეფასების მაჩვენებელი, ჭეშმარიტი კომპლექტი მთლიანად, შეფასებისგან, რომელიც ტიპიური ნიმუშია, არის საშუალო კვადრატული შეცდომა. უფრო მეტიც, უფრო მეტ შერჩევა, პატარა შეცდომა. ვარიაციის მაღალი ღირებულება განსაზღვრავს შეცდომის მაღალი ღირებულებას და პირიქით.
როდესაც არსებობს მხოლოდ ორი ვარიანტი დანიშნულ კითხვაზე, გამოითქვა პროცენტული მაჩვენებელი (პროცენტული ზომა გამოიყენება), ნიმუშის ზომა განისაზღვრება შემდეგი ფორმულით:

სადაც n არის ნიმუშის ზომა; Z არის ნდობის შერჩეული დონის საფუძველზე განსაზღვრული ნორმალიზებული გადახრა; P - ნაპოვნი ვარიაცია შერჩევისთვის; G - (100-P); E - დასაშვები შეცდომა.
გარკვეული კომპლექტის ვარიაციის ვარიაციის მაჩვენებლის განსაზღვრისას, პირველ რიგში, მიზანშეწონილია წვის წინასწარი თვისებრივი ანალიზის ჩატარება, პირველ რიგში, პირველ რიგში, დემოგრაფიულ, სოციალურ და სხვა ურთიერთობებში აგრეგატის ერთეულების მსგავსებაა ინტერესი მკვლევარს. საპილოტე კვლევის ჩატარება შესაძლებელია წარსულში ჩატარებული კვლევების შედეგების გამოყენების შესახებ. ცვალებადობის პროცენტული ზომის გამოყენებისას გათვალისწინებულია, რომ მაქსიმალური ცვალებადობა მიიღწევა P \u003d 50% -ისთვის, რაც ყველაზე ცუდი შემთხვევაა. გარდა ამისა, ეს მაჩვენებელი რადიკალურად არ იმოქმედებს ნიმუშის ზომაზე. გათვალისწინებულია მომხმარებელთა კვლევის დასკვნა შერჩევის მოცულობის შესახებ.
შესაძლებელია ნიმუშის ზომა განსაზღვროს საშუალო ღირებულებების გამოყენების საფუძველზე და არა პროცენტული ღირებულებების მიხედვით.

სადაც არის საშუალო კვადრატული გადახრა.
პრაქტიკაში, თუ ნიმუში ჩამოყალიბებულია და მსგავსი კვლევები არ განხორციელებულა, მაშინ ის არ არის ცნობილი. ამ შემთხვევაში, სასურველია სტანდარტული გადახრის ფრაქციებში E- ის შეცდომის შექმნა. გამოითვლება ფორმულა მოაქცია და იძენს შემდეგ ფორმას:
 სად
სად  .
.
ზემოთ იყო საუბარი ძალიან დიდი ზომის აგრეგატების შესახებ. თუმცა, ზოგიერთ შემთხვევაში, აგრეგატი არ არის დიდი. როგორც წესი, თუ ნიმუში აგრეგატის ხუთი პროცენტია, აგრეგატი ითვლება დიდი და გათვლები, რომლებიც ხორციელდება ზემოაღნიშნული წესების შესაბამისად. თუ ნიმუშის ზომა აღემატება აგრეგატის 5% -ს, ეს უკანასკნელი მცირეა და აღნიშნული ფორმულა შემოდის კორექტირების კოეფიციენტით.
ამ შემთხვევაში ნიმუშის ზომა განისაზღვრება შემდეგნაირად:
 ,
,
სადაც n არის ნიმუშის ზომა მცირე აგრეგატისთვის; N 0 - ნიმუშის ზომა გამოითვლება ზემოაღნიშნული ფორმულების მიხედვით; N არის საერთო მოსახლეობის მოცულობა.
ცხადია, მცირე ნიმუშების გამოყენება დროულ დანაზოგებსა და ფულს გამოიწვევს.
ნიმუშის ზომის გაანგარიშების ზემოაღნიშნული ფორმულები ეფუძნება იმას, რომ ყველა ნიმუშის ფორმირების წესები დაფიქსირდა და ნიმუშის ერთადერთი შეცდომა არის მისი მოცულობის გამო. თუმცა, უნდა აღინიშნოს, რომ ნიმუშის ზომა განსაზღვრავს შედეგების სიზუსტეს, მაგრამ არა მათი წარმომადგენლობა.
ეს უკანასკნელი განისაზღვრება შერჩევის მეთოდით. ნიმუშების ზომის გაანგარიშების ყველა ფორმულა ვარაუდობს, რომ წარმომადგენლობა გარანტირებულია სწორი პრობიბილიტური შერჩევის პროცედურების გამოყენებით.
მოცულობა, ნიმუში განისაზღვრება ანალიზური, კვლევის მიზნები, და მისი წარმომადგენლობა პროგრამის სამიზნე ინსტალაციაა. ეს არის პროგრამა, რომელიც ადგენს აუცილებელ ზოგად მოსახლეობას შერჩევისთვის. იქნება თუ არა ყველა მოსახლეობა ან მისი სპეციალური სტრუქტურული ფორმირებები, შესწავლილი ობიექტის ყველა ელემენტი, რომელიც მხოლოდ კრიტერიუმების განსაზღვრულ პროგრამას წარმოადგენს, ზოგადი მოსახლეობა ობიექტის პროგრამაში განსაზღვრული ყველა ერთეულია.
ზოგადად, ნიმუშის სტრუქტურის განმსაზღვრელი მიდგომის დროს, ზოგადად, შეუძლებელია, რომ მისი მოცულობის ზუსტად განსაზღვროს მისი მოცულობის განსაზღვრა მიღებული ინფორმაციის საიმედოობის განსაზღვრული კრიტერიუმით. ამ შემთხვევაში, ნიმუშის ზომა შეიძლება ემპირიულად განისაზღვროს. საზღვარგარეთ მარკეტინგული კვლევის საქმიანობა შეიძლება იყოს სახელმძღვანელო. ასე რომ, როდესაც მყიდველების შესწავლისას უზრუნველყოფილია ნიმუშის მაღალი სიზუსტე, მაშინაც კი, თუ მისი მოცულობა არ აღემატება საშუალო და მსხვილი საცალო ფირმების მომხმარებელთა მომხმარებელთა გამოკითხვების ჩატარებისას, გამოკითხულთა რაოდენობა (შერჩევის მოცულობა) მერყეობდა 500-დან 1000-მდე ადამიანი.
პირველადი ინფორმაციის შეგროვების მეთოდის შერჩევის პროცედურის ღირებულება და კვლევის ინსტრუმენტები ისაა, რომ ამ შერჩევის შედეგები განისაზღვრება როგორც მიღებული და ხანგრძლივობის შესახებ ინფორმაციის საიმედოობა და სიზუსტე და მისი ხანგრძლივობა და მისი მაღალი ღირებულება კოლექცია.
მოვლენების ალბათობის დასადგენად, თქვენ დაინტერესებული ხართ, ჩვენ ვიყენებთ შერჩევით მეთოდს: ჩვენ ვატარებთ ნ. დამოუკიდებელი ექსპერიმენტები, რომელთაგან თითოეული შეიძლება მოხდეს (ან არ მოხდეს) ღონისძიება (ალბათობა სთ მოვლენების გამოჩენა თითოეული ექსპერიმენტში არის მუდმივი). მაშინ ნათესავი სიხშირე P * მოვლენების გამოჩენა მაგრამ სერია ნ. ტესტები მიიღება როგორც წერტილი შეფასების ალბათობა. პ. ღონისძიების გამოჩენა მაგრამ ცალკე ტესტში. ამ შემთხვევაში, P * ღირებულება ეწოდება შერჩევითი წილი ღონისძიების გამოჩენა მაგრამდა R - საერთო .
ცენტრალური ლიმიტის თეორემის (Moorev-LaPlace Theorem) გამოძიების საფუძველზე, ღონისძიების შედარებით სიხშირე შეიძლება ითვლება ნორმალურად განისაზღვროს პარამეტრების მ (P *) \u003d P და
აქედან გამომდინარე, n\u003e 30, ზოგადი წილის ნდობის ინტერვალი შეიძლება აშენდეს ფორმულების გამოყენებით:

სადაც U KR მდებარეობს ლაფარის ფუნქციის ცხრილებში, მოცემული ნდობის ალბათობის გათვალისწინებით γ: 2f (U CR) \u003d γ.
მცირე ნიმუშის ზომა N≤30, შეცდომა ε განისაზღვრება სტუდენტური დისტრიბუციის მაგიდა: ![]() სადაც t kr \u003d t (k; α) და თავისუფლების K \u003d N-1- ის ხარისხების რაოდენობა α \u003d 1-γ (ორმხრივი რეგიონი).
სადაც t kr \u003d t (k; α) და თავისუფლების K \u003d N-1- ის ხარისხების რაოდენობა α \u003d 1-γ (ორმხრივი რეგიონი).
ფორმულები ძალაშია, თუ შერჩევა განხორციელდა შემთხვევითი კვლავ (უსასრულო ზოგადი კომპლექტი), სხვაგვარად, აუცილებელია შესწორების შესაცვლელად შერჩევის (ცხრილი) თავისებურება.
ზოგადი გაზიარების საშუალო შერჩევის შეცდომა
| ზოგადი აგრეგატი | უსასრულო | სასრული მოცულობა ნ. |
| შერჩევის ტიპი | განმეორდა | ტყვეობაში მოქცევა |
| საშუალო ნიმუში შეცდომა |
ფორმულები ნიმუშის ზომის გაანგარიშებისათვის შერჩევის ხელმისაწვდომი მეთოდით
| შერჩევის მეთოდი | შერჩევის რიცხვითი ფორმულები | ||
| შუა | წილი | ||
| განმეორდა | |||
| ტყვეობაში მოქცევა | |||
ზოგადი ამოცანები
კითხვა "მოიცავს მითითებულ ღირებულების P 0 ნდობის ინტერვალს?" - შეგიძლიათ უპასუხოთ სტატისტიკური ჰიპოთეზის H 0: P \u003d P 0. ვარაუდობენ, რომ ექსპერიმენტები ხორციელდება ბერნულის ტესტის სქემის მიხედვით (დამოუკიდებელი, ალბათობა პ. ღონისძიების გამოჩენა მაგრამ მუდმივი). ნიმუშის მოცულობით ნ. განსაზღვრავს P *- ის ნათესავი სიხშირე, რომელიც მოვლენის გამოჩენა: სად არის მ. - მოვლენების რაოდენობა მაგრამ სერია ნ. ტესტები. H 0 ჰიპოთეზის შესამოწმებლად, სტატისტიკას გამოიყენება სტანდარტული ნორმალური განაწილება საკმარისად დიდი ნიმუშით (ცხრილი 1).ცხრილი 1 - ჰიპოთეზა ზოგადი პროპორციით
ჰიპოთეზა | H 0: P \u003d P 0 | H 0: P 1 \u003d P 2 |
| ვარაუდები | Bernoulli ტესტი სქემა | Bernoulli ტესტი სქემა |
| ნიმუშის რეიტინგები |  |
|
| სტატისტიკა კ. |  |  |
| სტატისტიკური განაწილება კ. | სტანდარტული ნორმალური N (0,1) |
მაგალითი 1. შემთხვევითი ხელახალი შერჩევის დახმარებით, კომპანიის მენეჯმენტმა თავისი თანამშრომლების 900-ის ნიმუშის კვლევა ჩაატარა. რესპონდენტებს შორის 270 ქალი აღმოჩნდა. აშენების ნდობის ინტერვალით, 0.95-ის ალბათობით, რომელიც მოიცავს კომპანიის მთელ გუნდში ქალთა ჭეშმარიტ პროპორციას.
გადაწყვეტილება. პირობით ქალთა ნიმუშის წილი (ყველა რესპონდენტის ქალთა ნათესავი სიხშირე). მას შემდეგ, რაც შერჩევა მეორდება, და ნიმუშის ზომა არის დიდი (n \u003d 900) შერჩევის შეცდომა განისაზღვრება ფორმულა ![]()
ღირებულება u kr მოძებნა მაგიდა laplace ფუნქცია თანაფარდობა 2F (U CR) \u003d γ, I.e. ![]() LaPlace ფუნქცია (დანართი 1) იღებს ღირებულებას 0.475 საათზე u kr \u003d 1.96. ამიტომ, ლიმიტის შეცდომა
LaPlace ფუნქცია (დანართი 1) იღებს ღირებულებას 0.475 საათზე u kr \u003d 1.96. ამიტომ, ლიმიტის შეცდომა ![]() და სასურველი ნდობის ინტერვალი
და სასურველი ნდობის ინტერვალი
(P - ε, P + ε) \u003d (0.3 - 0.18; 0.3 + 0.18) \u003d (0.12; 0.48)
ასე რომ, 0.95-ის ალბათობით, შეიძლება გარანტირებული იყოს, რომ კომპანიის მთელ გუნდში ქალების პროპორციულია 0.12-დან 0.48-მდე.
მაგალითი 2. ავტოსადგომის მფლობელი კითხულობს დღეს "წარმატებულს", თუ ავტოსადგომზე 80% -ზე მეტი ივსება. წლის განმავლობაში ჩატარდა 40 პარკირების შემოწმება, რომელთაგან 24 იყო "წარმატებული". 0.98-ის ალბათობით, იპოვეთ ნდობის ინტერვალი წლის განმავლობაში "წარმატებული" დღის ჭეშმარიტი წილის შესაფასებლად.
გადაწყვეტილება. "წარმატებული" დღის ნიმუშის წილი არის
ლაქების მაგიდის ფუნქციაზე, ჩვენ ვიპოვებთ U CR- ს ღირებულებას
ნდობა ალბათობა
F (2.23) \u003d 0.49, u kr \u003d 2.33.
შერჩევის გათვალისწინებით შეუძლებელია (I.E., ორი ჩეკები არ ჩატარებულა ერთ დღეში), ჩვენ ვნახავთ ლიმიტის შეცდომას: ![]()
სადაც n \u003d 40, n \u003d 365 (დღე). აქედან ![]()
და ზოგადი წილის ნდობის ინტერვალი: (P - ε, P + ε) \u003d (0.6 - 0.17; 0.6 + 0.17) \u003d (0.43; 0.77)
0.98-ის ალბათობით, მოსალოდნელია, რომ წლის განმავლობაში "წარმატებული" დღის წილი 0.43-დან 0.77-მდე.
მაგალითი ნომერი 3. პარტიაში 2500 პროდუქციის შემოწმება, აღმოაჩინა, რომ უმაღლესი კლასის 400 პროდუქტი და N-M - არა. რამდენად გჭირდებათ პროდუქციის შემოწმება, რათა დადგინდეს უმაღლესი კლასის წილი 95% -მდე 0.01-მდე?
გამოსავალი ჩვენ ვეძებთ ფორმულას, რათა დადგინდეს შერჩევის შერჩევისას.
F (t) \u003d γ / 2 \u003d 0.95 / 2 \u003d 0.475 და ეს მნიშვნელობა ლაქის მაგიდაზე შეესაბამება t \u003d 1.96
შერჩევითი წილი W \u003d 0.16; შეცდომა Sampling ε \u003d 0.01
მაგალითი ნომერი 4. პროდუქციის სურათების მიღება ხდება თუ პროდუქტი, რომ პროდუქტი იქნება შესაბამისი სტანდარტი მინიმუმ 0.97. მიღებული სურათების შემთხვევით შერჩეული 200 პროდუქტი იყო 193 შესაბამისი სტანდარტი. შესაძლებელია თუ არა მნიშვნელობის დონე α \u003d 0.02 პარტიის მისაღებად?
გადაწყვეტილება. ჩვენ ჩამოყალიბებთ მთავარ და ალტერნატიულ ჰიპოთეზას.
H 0: P \u003d P 0 \u003d 0.97 - უცნობი ზოგადი წილი პ. მოცემული ღირებულება P 0 \u003d 0.97. პირობებთან დაკავშირებით - სავარაუდო, რომ მიღებული სურათების ნაწილი იქნება სტანდარტული, 0.97-ის ტოლი; ისინი. პროდუქციის სურათების მიღება შესაძლებელია.
H 1: P<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
სტატისტიკის დაცული ღირებულება კ. (ცხრილი) გამოთვალეთ მითითებულ ფასეულობებზე P 0 \u003d 0.97, N \u003d 200, M \u003d 193
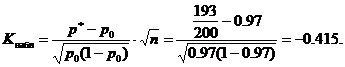
კრიტიკული მნიშვნელობა თანასწორობისგან ლაფარის ფუნქციის მაგიდა
![]()
პირობით α \u003d 0.02, ეს აქედან f (kkr) \u003d 0.48 და kkr \u003d 2.05. კრიტიკული რეგიონი მარცხნივ, ი.ა. ეს არის ინტერვალი (-9 კმ) \u003d (-, -2.05). Navel \u003d -0.415- ისთვის დაკვირვების ღირებულება არ არის კრიტიკული ადგილისთვის, ამიტომ, ამ მნიშვნელობის ამ დონეზე არ არსებობს მთავარი ჰიპოთეზა. თქვენ შეგიძლიათ მიიღოთ პროდუქციის პარტია.
მაგალითი ნომერი 5. ორი მცენარეთა იგივე ტიპის დეტალები. მათი ხარისხის შეფასების მიზნით, ნიმუშები მზადდება ამ მცენარეების პროდუქციაზე და მიღებულია შემდეგი შედეგები. პირველი ქარხნის 200-მდე შერჩეული პროდუქტი 20 დეფექტურია, მეორე ქარხნის 300-მდე პროდუქტში - 15 ხარვეზი.
მნიშვნელობა 0025, გაირკვეს, არის თუ არა მნიშვნელოვანი განსხვავება, როგორც ამ მცენარეების მიერ წარმოებული ნაწილები.
პირობით α \u003d 0.025, აქედან გამომდინარე F (CKR) \u003d 0.4875 და KKR \u003d 2.24. ორმხრივი ალტერნატივით, დასაშვები ღირებულებების ფართობი ფორმა (-2.24; 2.24). დაკვირვებული ღირებულება k navel \u003d 2,15 მოდის ამ ინტერვალის, I.E. ამ დონის მნიშვნელობას არ არსებობს მიზეზი, რომ უარყოს ძირითადი ჰიპოთეზა. მცენარეები იმავე ხარისხის პროდუქტებს ქმნიან.